Breathe new life into your ETL Processes
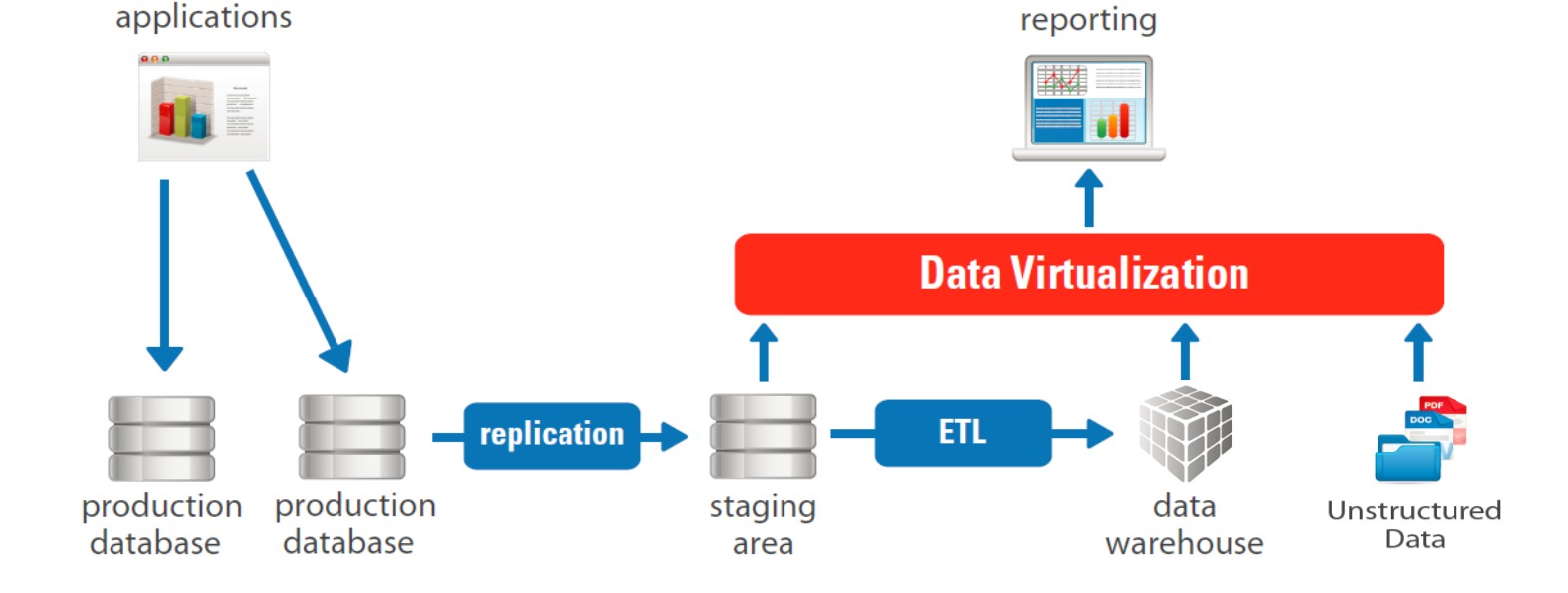
In many organizations, data integration still means using ETL processes to perform the traditional heavy-lifting of data replication and consolidation. While ETL is a tried and tested method for consolidating structured data into a data warehouse, it is certainly a stretch of the imagination to think of this as agile or flexible. In addition, ETL grew up in the days when typical data sources were structured nicely as rows and columns – a far cry from today’s world when data can, and does, come in every shape and format. This is not to say that your existing ETL tools and processes are useless and should be thrown away – far from it! There are some things that ETL handles very well, such as bulk copying of data, complex multi-pass data cleansing and transformations, and so on. If your ETL processes are performing these operations, leave them alone and let them continue to do their job.

However, if you need to integrate other ‘non-traditional’ data sources – such as Big Data from Hadoop or NoSQL data sources, unstructured data, or web or network data – you’ll need to enhance and extend your ETL processes with additional capabilities – to be more precise, with additional capabilities provided by data virtualization. A Data Virtualization platform can access the non-traditional data sources and expose the data as if it‘s standard SQL-compliant data. In other words, it appears as if it’s a table in a (virtual) relational database to an ETL process – or any other consuming application. This allows you to enhance your ETL processes to incorporate the now accessible unstructured data sources and enrich the data that you are storing in your data warehouse.
Alternatively, the Data Virtualization platform can access the data in the data warehouse and combine this will unstructured data before delivering this enriched data directly to consuming applications, such as BI tools. Depending upon the nature and flexibility of your ETL processes, this latter option – i.e. enrich the data pulled from the data warehouse rather than enrich it prior to storing it in the data warehouse – might be a better option.

There are many ways in which Data Virtualization can breathe new life into your ETL processes, to extend their capability to enhance the new data sources and formats. ETL is not dead…it just needs a helping hand!

- The Energy Utilities Series: Challenge 3 – Digitalization (Post 4 of 6) - December 1, 2023
- How Denodo Tackled its own Data Challenges with a Data Marketplace - August 31, 2023
- The Energy Utilities Series: Challenge 2 – Electrification (Post 3 of 6) - July 12, 2023