
In my previous posts, we reviewed some of the main optimization techniques used by Denodo in Logical Data Warehouse and Logical Data Lake scenarios (see here and here). We also provided real numbers showing that a logical architecture can achieve performance as good as a conventional physical architecture when the data virtualization system uses the right optimization techniques for each query.
But, how can the data virtualization (DV) system choose the right optimization technique/s for each query? The answer is cost-based optimization: for a given query, the DV system generates a set of candidate execution plans, estimates their cost, and chooses the plan with the lowest estimation.
That may sound very similar to how query optimization works in relational databases and, actually, most DV systems (and the “data virtualization” extensions commercialized by some Big Data vendors) rely on traditional database cost estimation methods, with only minimal changes. Nevertheless, this will often produce big estimation errors because traditional methods are designed for single-system scenarios, while a data virtualization query needs to combine data from several heterogeneous data sources. In turn, the cost-estimation process of Denodo is designed from scratch to take into account the nature of query execution in DV systems.
To illustrate the cost factors that a DV system needs to take into account, Figures 1 and 2 show two candidate execution plans for a query which combines product data stored in a conventional database with sales data stored in a parallel database. The query obtains the maximum discount applied to each product in the last 9 months. The discount applied is obtained by subtracting the ‘sale price’ (a field in the sales database) from the ‘list price’ of the sold product (in the products database). To fully understand the rest of this blog, you do not need to understand these plans in detail (although if you are interested, a step-by-step explanation is provided in this post). It is enough to get a general idea of the type of execution steps that compose a candidate plan for a query in a DV system. 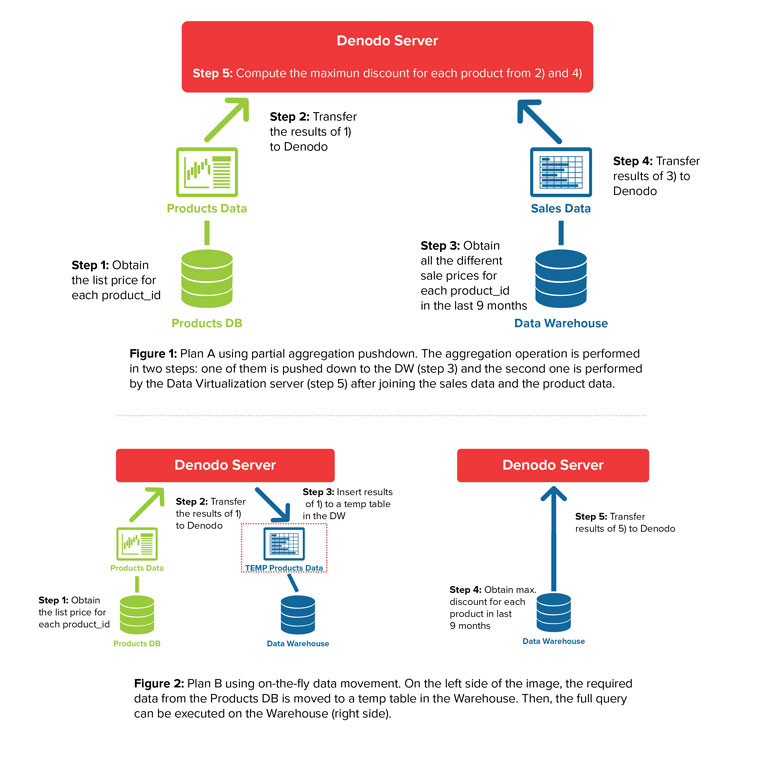
As you can see in the figures above, a query plan in a DV system is a combination of the following types of steps
- Pushing down queries to different types of data sources. In our example, Denodo pushes down queries to a conventional database (step 1 in plans A and B) and a parallel database (step 3 in plan A, and step 4 in plan B). In many scenarios, we will also find other types of data sources, such as Hadoop clusters or SaaS applications.
- Transferring data from the data sources to the DV system. In our example, this is needed in steps 2 and 4 in plan A, and steps 2, and 5 in plan B.
- Inserting data into a data source. The ‘on-the-fly data movement’ optimization technique, used in plan B, works by moving a small dataset from one data source to a temporal table in another data source. This way, the moved dataset can be combined in-place with the datasets of the target data source. Therefore, estimating the cost of this operation requires being able to estimate data insertion costs (step 3 in plan B).
- Post-processing and combining partial query results in the DV system (step 5 in plan A).
Let’s now analyze what information we need to successfully estimate the cost of these types of steps.
First, as in cost-based optimization in relational databases, the DV system needs statistics about the relations participating in the query. These statistics allow estimating the size of the input data for each step in a query plan, which is obviously a crucial factor influencing the cost of all types of steps.
Since the DV system does not have the actual data stored locally, it cannot generate the statistics as in a conventional database. Denodo solves the problem of obtaining accurate statistics in two ways:
- If the data source maintains its own data statistics (as is the case in most databases), Denodo can obtain them directly from the data source catalog tables.
- If the data source does not maintain statistics or they are not accessible to external programs, Denodo can execute predefined queries against the data source relation to compute the statistics.
Second, the DV system needs information about the indexes (and/or other physical data access constructions) available in the data sources. The performance of the queries pushed down to a data source may change in orders of magnitude depending on the indexes applicable to the query. Denodo automatically obtains indexes information from the data sources which expose such information (as most databases do), or allows the user to declare them when Denodo cannot obtain them automatically.
Third, to estimate the cost of the queries pushed down to the data sources, the DV system needs a different cost estimation model for each type of data source because the performance differences between them can be huge. It is not enough to apply simplistic correction factors to account for these differences (e.g. assuming that parallel databases will resolve every query n times faster). For some queries, parallel databases are orders of magnitude faster than conventional databases, for others, the differences can be minimal or inexistent. Therefore, accurate estimations need detailed calculations taking into account the internals of the query execution process in each system.
It is also necessary to take into account some features of the data source hardware, for instance, the cost of executing a query in a parallel database with, say, 96 processing cores is very different than executing the same query with 48.
Notice also that the cost of inserting data in a certain data source (action type 3), can also be very different depending on the type of data source, so this also needs to be considered.
To take into account all these factors, Denodo has specific cost estimation models for the main types of data sources typically found in Logical Data Warehouse/Data Lake scenarios, including conventional databases, parallel databases and Hadoop clusters.
Finally, the DV system also needs to consider the relative data transfer speed from each data source. For example, the cost of obtaining 100.000 rows from a local database is very different than obtaining them from a SaaS application like Salesforce. Denodo allows specifying data transfer factors to take into account the relative differences in the transfer rates between the DV system and the different data sources.
As conclusion, to the best of our knowledge, Denodo is the only DV system in the market that takes into account data source indexes, data transfer rates and the query execution models of parallel databases and Big Data sources. Some “data virtualization extensions” of conventional databases and Big Data systems do not even consider statistics for virtual relations. Without all this information, it is not possible for the DV system to automatically determine good execution plans. In the best case scenario, this means that you will be forced to manually optimize each query, with the associated cost increment and agility loses. In the cases where you cannot manually modify the queries (e.g. the queries generated by a BI tool), you will suffer poor performance.
Therefore, our advice is: when evaluating DV vendors and Big Data integration solutions, don’t be satisfied with generic claims about “cost-based optimization support,” ask for the details about the information those methods consider and the decisions they can make automatically to know the performance you can expect from them.

- From Ideas to Impact: The GenAI Q&A for Innovation Leaders - June 11, 2025
- GenAI, Without the Hype: What Business Leaders Really Need to Know - June 11, 2025
- The GenAI Q&A: What Every Data Leader Needs to Know - May 29, 2025
Nice explanation Alberto,
Does this mean that Denodo can ‘learn’ it’s environment the more it is used?
I mean will the execution plan recalculate all this for every query on-the-fly, or will it look at historical information and then be able to use that as part of its decisions.
It is an interesting area to consider, that the DV system could not only use direct information, but also start to understand the topology and performance characteristics of a distributed data system either in the cloud or as a hybrid.
I wonder whether a number of specifically designed queries should be run after an initial model, in order to help the product establish its understanding of the cost optimisation plane?
Thanks Jay, that is a very interesting question. Denodo does not “learn” the cost information from the past system activity. I will talk a little about that approach later, but first let me clarify the approach we actually use.
First, Denodo runs a ‘statistic generation’ process for each base view (‘base views’ are those which directly correspond with a data source relation). This process obtains statistics about the relation such as the max/min value for each field, the num of distinct values, etc. For base views coming from databases, Denodo can obtain such statistics directly from the database catalog. For base views from other data sources (e.g. web services), Denodo executes a series of queries on the source to obtain the statistics. Denodo also automatically introspects the indexes from most databases, and allows declaring them for those databases where such information cannot be obtained.
Regarding topology information (such as the number of processing nodes in a parallel database or a cluster), Denodo already knows the typical values for some data sources. For instance, if you say you are using a particular version of the Netezza appliance, Denodo will assume a particular number of processing nodes and disk slices, but you will be able to manually change those settings. For network transfer speed, Denodo allows to specify scale factors to take into account the differences in the transfer rates between Denodo and the different data sources.
Now, let me go back to the approach of “learning” cost information. It is an idea we have extensively explored from a research point of view and we have even prototyped it in our Labs. In our experience, the approach is attractive when it is not feasible to obtain from the data sources statistics that describe the data accurately. This can happen, for instance, with some types of web services. Nevertheless, the approach tends to perform worse with queries which deviate from the norm. In turn, collecting general statistics about the dataset, allows you to do a good job with any query, even if you have never seen a similar one in the past. Combining both approaches to have the best of both worlds is an interesting research direction for the Denodo Roadmap.