
Software systems designers often structure their thinking around the underlying functional and data/information components of their desired applications. This approach—analogous to the scientific method of breaking a system into its smallest sub-parts in order to understand how it works—forms the basis of traditional architectural patterns, such as the data warehouse, as we saw in part II of this series. Data fabric, as seen in part I comes from similar thinking. The data lakehouse, on the other hand, appears to derive its functional foundation more from existing products than decomposition of functionality. Now, time to talk about Data Mesh.
Introducing the Data Mesh Approach
The designers of the data mesh approach start from yet another distinctly different place. Starting with her seminal article in May 2019, Thoughtworks’ Zhamak Dehghani introduces data mesh as an alternative to “the centralized paradigm of a lake, or its predecessor data warehouse.” Denodo’s Alberto Pan offers a concise summary of the problems of a centralized architecture—limited business understanding in the data team, inflexibility of centralized systems, and slow, unresponsive data provisioning—that drove the evolution of data mesh. The solution, according to Dehghani is “that the next enterprise data platform architecture is in the convergence of Distributed Domain Driven Architecture, Self-serve Platform Design, and Product Thinking with Data.”
Dehghani admits this to be a buzzword-laden definition. However, at its core is the concept of domain-driven design, a seemingly simple idea that the structure and language of software should match the “business domain” in which it operates. The approach has been successfully applied in (operational) application development, has influenced the decomposition of applications into services based on business domains, and has driven the rise of the microservices architecture. In data mesh, the concept is applied to data, leading to a data architecture where business units[1] take responsibility for the data they need, from initial creation to consumption. This is a model build on the ownership of data as “products” by business units. Dehghani says: “Instead of flowing the data from domains into a centrally owned data lake or platform, domains need to host and serve their domain datasets in an easily consumable way,” leading to a self-service mindset for data use. The figure below shows Dehghani’s very high-level architectural pattern for a data mesh.
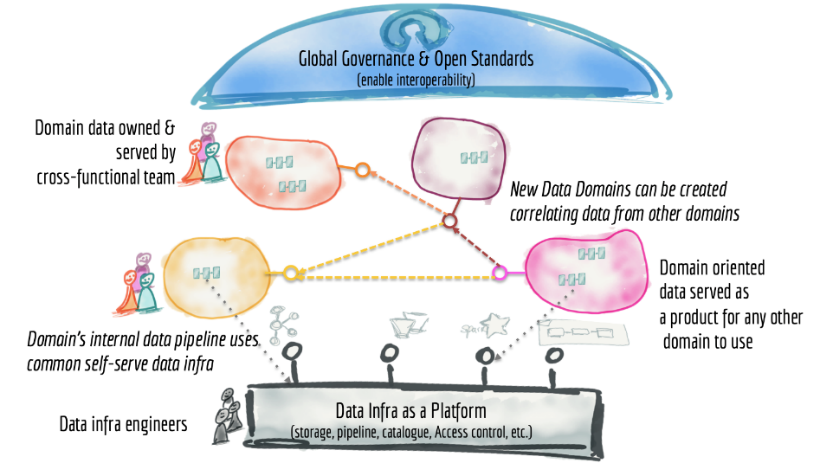
Of particular interest is that the technical infrastructure is reduced to a single box, placing the focus firmly on the concept of data domains and how they are created, owned, and used by businesspeople. Functional components and data stores are omitted. The architecture majors on how data should be managed by domain and how other domains request or “pull” data from the creative domains. Observe also the “Global Governance and Open Standards” construct. This is a box seldom seen in functional architectures because so much of it depends on organizational constructs and largely manual processes.
Dehghani’s concise definition of the building blocks of a data mesh platform is: “distributed data products oriented around domains and owned by independent cross-functional teams who have embedded data engineers and data product owners, using common data infrastructure as a platform to host, prep and serve their data assets… an intentionally designed distributed data architecture, under centralized governance and standardization for interoperability, enabled by a shared and harmonized self-serve data infrastructure.”
As defined in a subsequent article, a data product consists not only of data and metadata, but also of the code for creating it from its sources, allowing access, and enforcing policies, as well as the infrastructure to build and store it. This service-oriented architecture (SOA) approach is unique to data mesh over all the other patterns we have explored.
Data Mesh Discussion
A data architecture with governance in pole position can only be a good thing. So too is a focus on addressing the issues of siloed data storage and delivery schemes, particularly as the analytical environment becomes both more complex in structure and demands ever more timely delivery.
However, experienced data warehouse architects will probably be concerned about how data from different domains can be reconciled and made consistent, given the encapsulated nature of data products and their independent development by different teams. The traditional solution to this reconciliation problem is, of course, to bring data together in an enterprise data warehouse structure, an approach explicitly excluded by the data mesh. Another approach, however, can be used. This consists of an overarching, integrated data model combined with data virtualization technology, as outlined by Pan in the previously referenced blog post.
Both approaches require some level of up-front definition of an over-arching information or semantic model to ensure cross-domain interoperability. Dehghani does not discuss this topic. The risk, therefore, may be that siloed data pipelines are replaced by siloed data domains.
Conclusion
Data mesh offers a new and unique approach to the challenges of providing an environment for decision-making support and analytics systems. Its focus on delivering, managing, and using data in a domain-oriented paradigm offers much needed and novel insights into the organizational challenges of such systems. However, adopting a microservices approach to data may be too big a step for many more traditional data warehouse and lake shops. And product support for some aspects of the architecture is still in the early stages of evolution. As a result, data mesh may be more suited to larger businesses with complex data analytics needs and mature IT organizations.
As we’ve considered the three architectural patterns—data fabric, data lakehouse, and data mesh—over this and the previous two blog posts, it should be clear that there exist multiple approaches to stepping up to the promises of digital business and addressing the problems associated with delivering the actual data and information. Among these three approaches—as well as data warehouse, logical data warehouse, and data lake—none can be chosen as a clear winner, nor can any be dismissed out of hand. Each has its strengths and weaknesses; each addresses a particular aspect of the challenges of data management.
Data architects embarking on creating new or extending existing decision-making support and analytics environments would be well advised to study all these competing and complementary architectural patterns with a view to weaving the most appropriate solution for their specific situation.

- The Data Warehouse is Dead, Long Live the Data Warehouse, Part II - November 24, 2022
- The Data Warehouse is Dead, Long Live the Data Warehouse, Part I - October 18, 2022
- Weaving Architectural Patterns III – Data Mesh - December 16, 2021