
2019 is the year of the data-driven organization. The more data an organization collects, the more insights they will have, right? Well no actually, it’s more about how you glean the insights from the data rather than how much data you have collected. The challenge many organizations face is that as their repositories multiply in number, so too does the number of data silos that are created. The data becomes scattered across multiple operational and analytical systems, making it very difficult to integrate, and as a result, insights are few and far between; hardly the best environment for a “data-driven” organization.
Tackling the Silos, the Traditional Way
Typically, organizations will turn to bulk/batch ETL processes, loading their siloed data into an enterprise data warehouse to achieve an integrated view. While this method worked in the past, with the steady increase of data streams (for example, distributed mobile devices, consumer apps and applications, multichannel interactions and even social media interactions), implementation can take up to 12-24 months. By which time, the data is out of date and dashboards/analytics may need to be reworked. This timeframe is no longer practical for data-informed decision-making and business agility.
A Tool to Focus on Vision and Execution
Organizations need highly sophisticated architectures to integrate multi-channel interactions, and a tool which enables them to focus on execution. Such technologies, namely data virtualization, are gaining momentum alongside and even superseding the traditional methods that have held their position in the market for so long.
Data virtualization technology maps the data from disparate sources (i.e on-premise data, cloud applications or other external ones) and creates a virtualized layer which can then be seamlessly exposed to consumer applications. This approach is significantly faster since the data need not be physically moved from the source systems.
Contrary to popular belief, data virtualization is not a replacement of the enterprise data warehouse, nor ETL, but rather a complementary solution. It does not create an historical data layer, it creates a virtual one on top of operational systems, which serves as a common, integrated and unified source of information and insights that all downstream applications including reporting tools can use.
What to Look Out for In A Data Virtualization Tool
As a result of market traction and additional features and functionalities being added to data virtualization solutions, such as Massive Parallel Processing (MPP) and dynamic query optimization, it has become a technology of interest for many traditional data integration, database and application tool vendors.
The four main types of vendors are:
a. Stand-alone solution providers
b. Traditional data integration vendors incorporating data virtualization capabilities into their existing solutions either as a separate product or a complementary capability.
c. Database vendors extending access to the data through data virtualization (e.g. database links)
d. BI/Analytics tools providing a virtual semantic layer which developers or advanced business users use to develop reports, dashboards or ad-hoc analysis.
The below diagram represents a full-featured data virtualization platform:
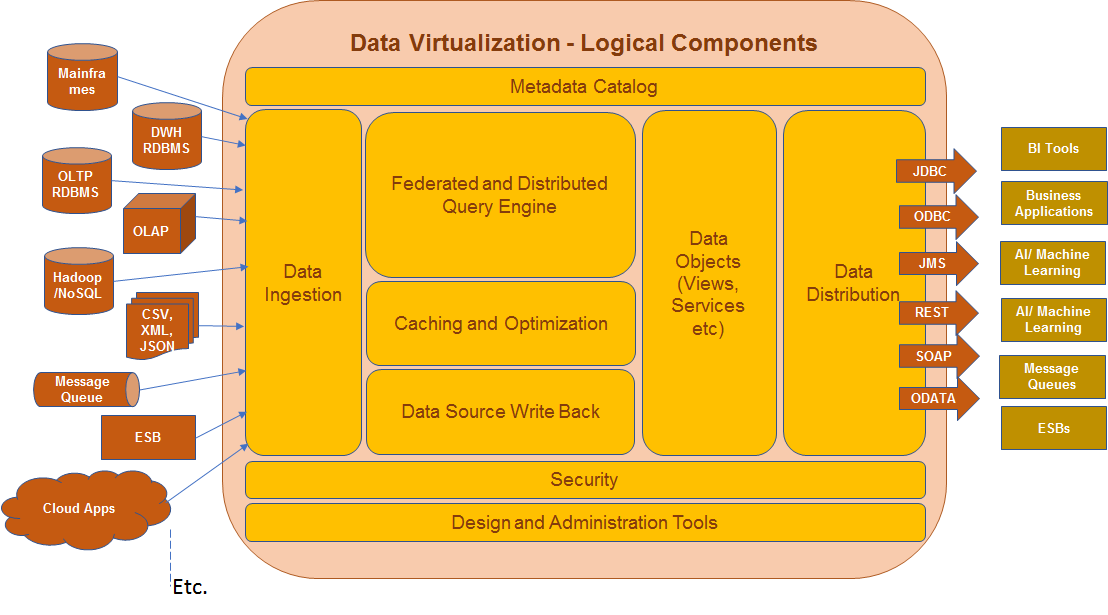
What Do All the Functionalities Do?
- Data Ingestion: This includes connectors to enable access to data from various databases, big data systems (Hadoop, NoSQL etc), enterprise service bus, message queues, enterprise applications (including ERPs and CRMs), data warehouses and data marts, mainframes, cloud data systems, SaaS applications, and various file types.
- Security: Provides authentication and authorization mechanisms to ensure data governance.
- Federated and Distributed Query Engine: This is the core component of any data virtualization technology. It accepts incoming queries and creates the most efficient execution plan by breaking the incoming query in to multiple subqueries which can then be sent to source systems via data ingestion layer. The retrieved datasets are then joined in memory to create a composite data view through which data is made available to the client application.
- Data Objects: Typical implementation will have a hierarchy of views and data services which encapsulates the logic.
- Caching and Optimization: This improves the performance of the incoming queries.
- Data Distribution: This exposes the data in response to the queries received by it through various protocols. A typical consumption layer publishes data in various formats including JSON and XML and supports Web Services (REST and SOAP), JDBC, ODBC, OData, and Message Queues.
- Design and Administration Tools: This includes tools for graphic design and the import/export of data objects, integration of source code configuration management tools like subversion and TFS, administration and configuration. Some of the advanced tools also provide intelligent recommendation on design.
- Data Source Write Back: The ability to write the transformed data back to the source from which the data was initially extracted is becoming increasingly common. Many of the new age tools are now allowing users to write back the data either as new records or updates to existing ones.
- Metadata Catalog: Data virtualization tools may primarily support two types of meta data
a. Design and configurations – This includes metadata related to source systems, mapping of the source systems with logical data objects creation during design activities, run time execution data. This could be stored either in the XML or proprietary format. This also helps in sharing the metadata with other data management tools performing data quality, ETL, master data management functions.
b. Additional catalog – The design and configuration data may need to be queried. Many of the tools provide additional cataloging features which enable business users to tag and categorize the metadata element.
Today’s organizations are leveraging data virtualization for a number of use cases:
• To insure a seamless journey to the cloud
• To insure against risk during legacy modernization
• Operational effectiveness
• Advanced customer analytics,
• Risk data aggregation,
• Mergers and acquisitions,
Given its building momentum in the data integration space, and the acknowledgement of its capabilities in creating more sophisticated architectures, data virtualization is the technology of the moment. We are excited to see more innovation and adoptions in this space.
NIIT Technologies is a leading global IT solutions organization, enabling its clients to achieve real world business impact through unparalleled domain expertise working at the intersection of emerging technologies. NIIT Technologies and Denodo are working together to provide data virtualization solutions for three key verticals: banking and financial services, insurance and travel and transportation.
With their combined strength and cutting-edge capabilities in analytics, cloud modernization, cognitive automation, industrialized AI, they are helping clients to innovate their business by automating processes, make better decisions and ultimately, to become data-driven.

- Data Virtualization: A Unified Platform for Insights - February 27, 2019