
Data Governance as a concept and practice has been around for as long as data management has been around. It, however is gaining prominence and interest in recent years due to the increasing volume of data that needs to be managed on the one hand, and the growing scrutiny around how organisations store and manage these data. Regulations such as GDPR means that data governance is no longer a “nice to have” but a critical requirement that can potentially lead to costly consequences for organisations.
To make matters worse, the increasingly complex data infrastructure landscape means that it has never been more challenging to secure and govern your data. The relentless march to the cloud and the deployment of complex data lakes solutions are only adding to the complexity equation today.
To deal with the increasing demand and complexity, it is then essential for organizations to simplify their approach to data governance. Here we discuss 3 ideas you should consider that can simplify your approach to data governance and lead to reduced cost and risk of non-compliance.
It has never been more challenging to secure and govern your data
Minimise Data Copies
As obvious as it sounds, the best way to simplify how you protect and govern your data is simply to try to have less of it!
Unfortunately, data copies and replications are considered the norm in enterprises today. The same transaction record can exist in the source system, the data lake, the EDW, the on-premise analytical data mart and the cloud database. This makes it difficult to manage a single version of the truth, and also means that there are multiple copies of the data to govern and protect, which can create an administrative nightmare. Having more data copies also means more attack surfaces for cybercriminals who are always after your customer data.
The best way to simplify how you protect and govern your data is simply to try to have less of it
One of the easiest things an organisation can do today to simplify its approach to data governance is to eliminate or minimise the number of data copies within the organization. A logical data fabric leveraging data virtualization technology means that instead of creating new analytical data marts or additional downstream data repositories to support new use cases and data requirements, virtual data views can be created on top of existing data repositories. This means that less data needs to be replicated or copied and that a single authoritative data source can often be maintained.
A tangible benefit of only having minimum data copies is the ease of enforcing compliance activities. Organizations within the GDPR jurisdictions today need to execute many “right to be forgotten” requests. Having fewer copies of data means that less data copies need to be found and deleted, thereby reducing the overall cost and efforts. Incidentally, the ability to simplify the data architecture and streamline the audit process is why organisations such as Autodesk rely on Denodo for their GDPR related compliance tasks.
With data virtualization, organizations can enable real-time, interactive access to data across the entire data landscape. It still allows users to create consolidated data views critical for data insights, except without the nightmare of having multiple versions and copies of the same data.
Centralised Data Access Control and Monitoring
In a highly distributed data landscape, organizations must always maintain complete control and understanding of who has access to what data. This however, is often easier said than done. Different data repositories and technologies all have different approaches in terms of access control, even without the added complexity of granular row-level and column-level data access control. Furthermore, when changes are needed in terms of user access control, it can often require the involvement of multiple teams and multiple systems.
A logical data fabric layer leveraging data virtualization technology can help centralise and simplify data access control and monitoring within a single control plane. By mapping all the data sources into a logical data fabric layer and centralize all data access points, it can dramatically simplify the data access control process.
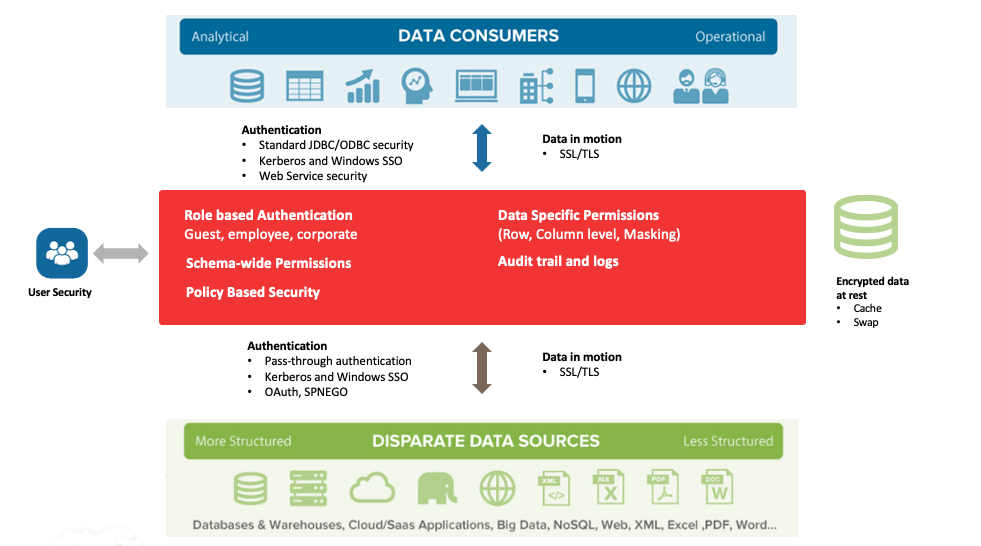
This simplified approach makes it much easier to take a domain-specific approach to data access popularised by the data mesh principle. A domain team or group can be defined once within the data virtualization layer, which can then be used to map granular access control over the entire data estate. This provides the agility needed by the business whilst at the same time allowing IT to enforce global as well as local level data access control.
By collecting all operational and active metadata within a single platform, organisations can also easily and confidently track and report all data usages and activities regardless of the underlying data repositories or the end-user BI tools used. This is especially useful in terms of tracking and monitoring access to sensitive data.
Having a single, centralised system that stores all active metadata also means powerful AI/ML-based capabilities such as a data catalog recommendation engine can be enabled.
These capabilities use the insights generated from historical activities and can be leveraged to improve system performance, drives automation, and improve self-service capabilities.
By collecting all operational and active metadata within a single platform, organisations can also easily and confidently track and report on all data usages and activities
De-Couple your Data Security Policy from the Data Repository
Data security policies go to the heart of any data governance implementation as it defines the rules and policies for how individuals and groups can access data and the kind of access they are allowed. It is an extension of basic role-based access control and often requires additional, contextually relevant business rules to be defined. Data security policies can allow the data science team to access and view detailed customer profile information whilst hiding and masking sensitive PII data on the fly. Global data security policy is all about providing the right data to the right person at the right time and ensuring that it is done in a scalable and cost-effective way.
Historically, these types of data security policies are often implemented at the database level (as database views, for example) as there weren’t many data repositories, and the data policies needed were much more straightforward. However, these database-centric approaches can be costly to maintain and change, requiring specialist skills (such as SQL) and can often lead to an explosion of multiple views across multiple systems.
Modern data security policies that support data regulation and compliance are often more complex and require fine-grained controls that must be applied in real-time. From an organisational perspective, data security policy is often the responsibility of the data governance or data stewards team today. These people usually lack technical or advanced SQL skills, often making a database-centric approach to data security policy difficult and unfeasible.
Modern data security policies that support data regulation and compliance are often more complex and require fine-grained controls that need to be applied in real-time
Data management platforms such as Denodo take a technology-agnostic approach to global data security policy implementation and simplify the process of defining and updating data security policies. This simplicity is achieved by decoupling the data security policy from the underlying data repositories. By implementing the necessary business rules at the logical data layer, they can be defined once and applied across all data repositories and BI tools. New data sources, users and BI tools can be easily added and mapped to existing data security policies.
Denodo takes decoupling even further and allows you to link data policy to semantic objects (tags) instead of directly against any virtual views or columns. This provides even more flexibility and scalability. For example, a single PII data security policy can be maintained and linked to a PII tag that maps to all the PII related tables and columns that need to be redacted across the entire enterprise (potentially hundreds of tables and columns). A change to any PII-related data security requirements only needs to be reviewed and updated via a single global data policy. This approach dramatically simplifies and reduces the ongoing effort associated with securing and governing your customer’s PII data.
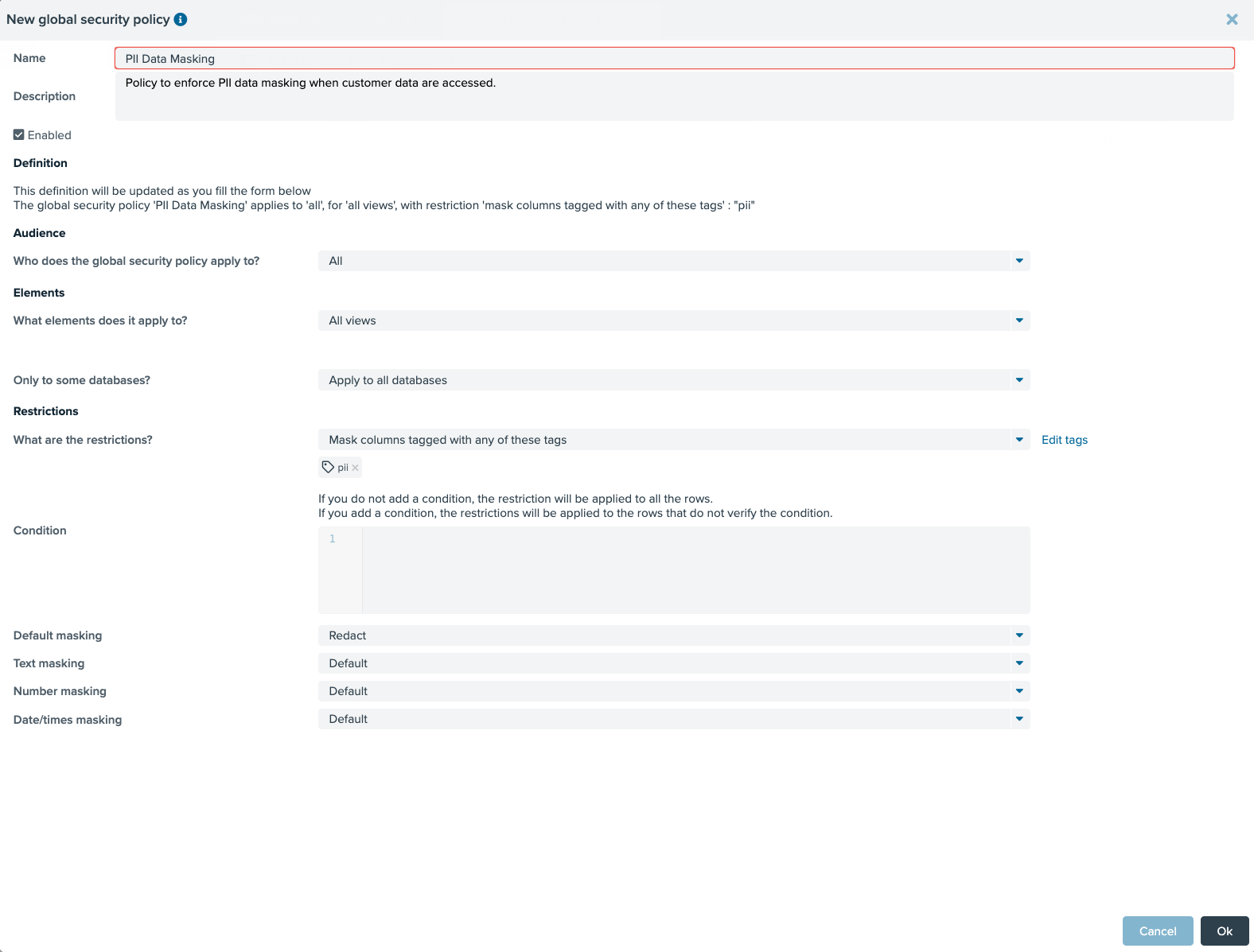
As shown in the above screenshot, Denodo data security policies can be easily defined via a drag and drop GUI with no code or specialist SQL skills required. This simplifies the implementation process and broadens the scope of who can create and maintain these types of global data policies.
In an age of increasing complexity in all aspects of data technology and architecture, organisations need to simplify their approach to data governance to succeed. While simple, the ideas discussed here can simplify and significantly affect any data governance initiative. Coupled with data virtualization technology, we believe every organisation can take advantage of these ideas and transform their approaches to data management and data governance regardless of their specific industry vertical or business function.
- Closing the Lakehouse Gap: From Data Storage to Data Delivery - March 26, 2026
- Build AI-Ready Data Products with Denodo - October 16, 2025
- From Chatbots to Agents: Navigating the Future of AI - July 3, 2025