
Organizations today need a data architecture that can overcome a double challenge: satisfy new business needs that require more agility and self-service capabilities, while at the same time dealing with a growing, diverse, and fast-moving data ecosystem (new data sources, data distributed across hybrid and even multi-cloud environments).
Data virtualization offers an abstraction layer between data storage and data consumers. This enables, on the one hand, modifications to the data infrastructure and data models in a very agile way, without affecting client applications, and on the other hand, it provides unified query access and data governance on top of that changing data infrastructure.
For this approach to be successful, it is essential to give the users not only a centralized-like experience in terms of data access but also in terms of performance.
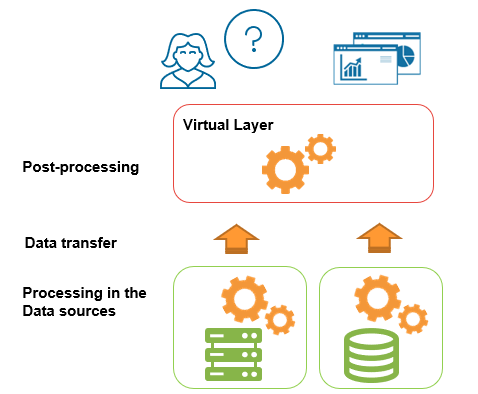
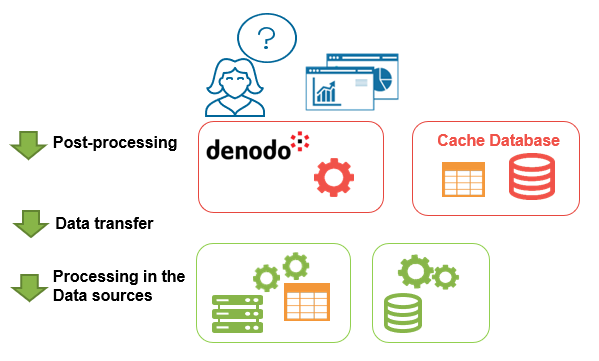
When a user sends a query to a data virtualization tool, it will send some of the processing to the data sources, retrieve these partial results, and combine them to build the final answer. This means there are three main factors we need to take into account in terms of performance: The processing in the data sources, the data transfer from these systems to the virtual layer, and the processing in the virtual layer (see figure above).
In previous posts we have already discussed how a smart and powerful query optimizer can evaluate alternatives and decide what is the best way to orchestrate the different query operations to minimize data transfer. We have also shown how these optimization techniques make a virtual solution achieve a level of performance that is comparable to that of a physical data warehouse.
In this post, I want to talk about a new optimization mechanism included in Denodo Platform version 8.0, which goes even further in speeding up queries in single and multi-data source environments, which is especially important in hybrid cloud scenarios.
But before I say more about this new acceleration technique, let me do a quick review of the mechanisms in previous versions of the Denodo Platform that accelerate analytical queries.
The Query Optimizer Module
To illustrate the different capabilities, I will use a simplified scenario consisting of a retailer company with data about sales and stores distributed among three different systems:
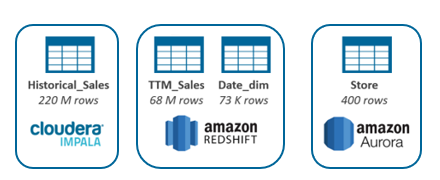
- A Cloudera Impala system, containing 220 million rows of historical data about sales
- An Amazon Redshift system, containing 68 million rows from the recent sales and the date dimension
- An Amazon Aurora system, containing information about 400 different stores.
The schemas and data we will use for these tables are defined by TPC-DS, the most important standard industry benchmark for decision support systems.
Using a data virtualization tool like the Denodo Platform, you can connect to these systems, import the metadata to model the different entities, and start executing queries.
For every query that you send, there are usually multiple different possible paths to get the same result. The query optimizer works behind the scenes, exploring and deciding what strategy would obtain the best result for each case.
These techniques can consist of: reordering the query operations to maximize the push-down to the data sources (aggregation push-down, Join-Union Push-Down, Join reordering), removing or simplifying operations (Branch pruning, Outer to Inner) or even creating temporary tables in one data source with part of the data in another data source (Data movement, MPP acceleration). A previous post describes these mechanisms in more detail.
The optimizer can take into account statistics of the tables like number of rows or number of different column values, and other useful information, like the existence of an index or a referential constraint to estimate the cost of each alternative and make the final decision.
The main goal is to reduce data transfer and post-processing as much as possible.
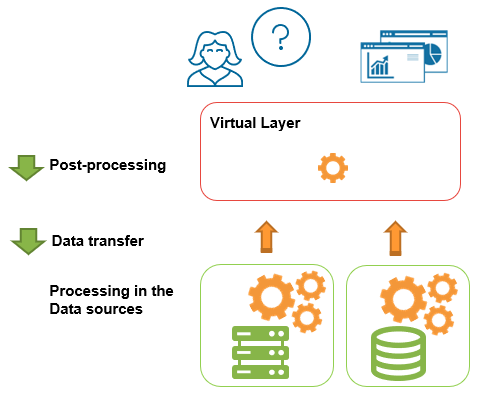
The query optimizer in Denodo Platform 7.0 already has a powerful engine that allows very good performance in real-time queries with no replication needed.
Smart Query Acceleration for Analytics
The new version of the Denodo Platform, Denodo Platform 8.0, includes a mechanism called Smart Query Acceleration for Analytics, which can significantly increase the performance for both single and hybrid scenarios, and it is especially useful in self-service environments.
This new feature is based on the fact that on analytic scenarios, many queries follow the same, or very similar, common patterns. For instance, if you ask for the total sales by year, or the average sales by store, in both cases the optimizer will probably choose a partial aggregation over the sales table and then combine that partial result set with the necessary dimensions to provide the final aggregation.
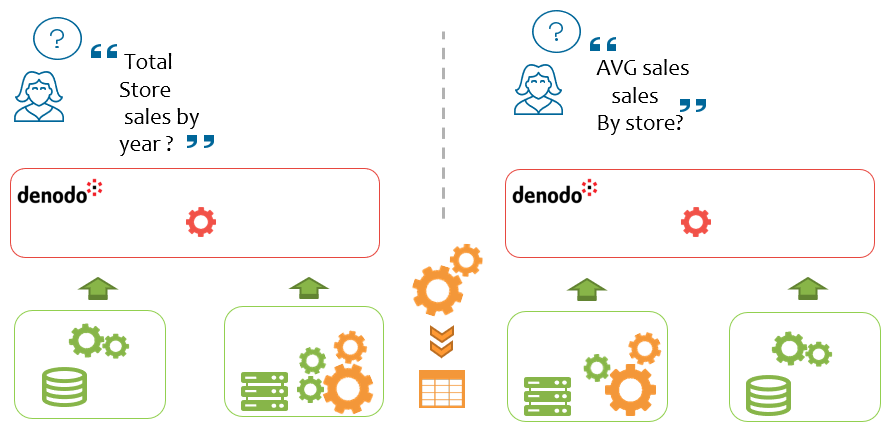
The idea behind Smart Query Acceleration for Analytics is to identify those common patterns among queries, persist these common result sets in a different table called “summary,” and then automatically detect whether it is possible to use them to accelerate a new query.
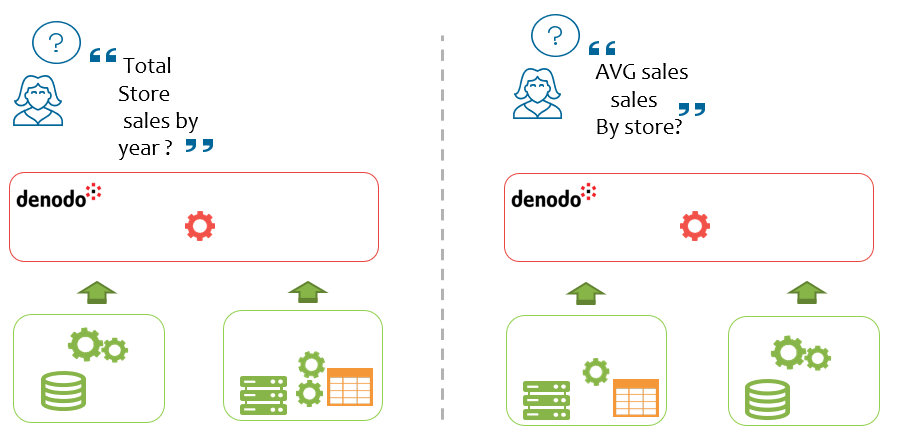
This is similar to the concept of aggregation awareness in some BI tools and OLAP databases, but with an important extra advantage: having these aggregates, or summaries, in the virtual layer means that all data consumers can benefit from it, no matter which tool they use to access the data, and you can create these summaries over any data source.
Smart Query Acceleration for Analytics drastically reduces processing and data transfer, and it is completely transparent to the user. In addition, one summary can help answer multiple queries.
For example, following the same use case of the retailer company as before, let’s imagine we want to avoid accessing Impala, where the historical data is located, and we create a summary in Redshift, where the recent sales and the date dimension are stored. We decide to store the total sales by store id and day of the sale using the following query:
|
SELECT ss_store_sk AS store_id, ss_sold_date_sk AS date_id, sum(ss_net_paid_inc_tax) AS total_sales, count(*) AS count_sales FROM store_sales GROUP BY ss_store_sk, ss_sold_date_sk |
This summary will contain around 350,000 rows and can help accelerate not only that specific query but many more. The following table shows several different queries, all of them combining sources with millions of rows:

In all of them, the optimizer is able to use that same summary, avoiding accessing the historical data and providing big performance benefits.
Using this new acceleration technique is beneficial in multiple use cases, but there are two scenarios where this feature is key:
- Self-service initiatives: Cases where the virtual layer contains a canonical model with different entities that the final user understands (like sale, customer, store) and there is limited control over the queries a user can send to combine that data, (for instance if they generate a new report from a BI tool). With Smart Query for Analytics, the user does not need to care about tuning the query or using a certain pre-canned view that is faster than another one. The query optimizer works behind each query to analyze if there are summaries available that can answer part of the query, and then it chooses between them to get the fastest result.
- Hybrid environments with cloud: Gartner predicts that “through 2025, over 80% of organizations will use more than one cloud service provider (CSP) for their data and analytics use cases.” If you are in the journey to the cloud, you will probably need to combine data that is still on-premises with data that is already in the cloud. If you already have a multi-cloud scenario, you will probably want to combine data from different cloud providers. In this hybrid environment, it can be very useful to create a few summaries in the cloud that combine data from the sources that have not been migrated yet, or from sources in other cloud locations. This way, in most cases you will avoid having to go to those other systems for data.
The new Smart Query Acceleration for Analytics included in Denodo Platform 8.0 can accelerate both single source and hybrid scenarios in a completely transparent way. End users can experience remarkably faster queries, while system administrators and developers can benefit from a more agile and flexible architecture with minimum resources.
If you are interested in seeing this new feature in more detail, take a look at this webinar by Denodo’s director of Product Management.

Among her contributions to the Denodo Platform she has led the design and development of some of the key features of the query optimizer module.
- Using AI to Further Accelerate Denodo Platform Performance - September 9, 2021
- Increase the Performance of Your Logical Data Fabric with Smart Query Acceleration - October 28, 2020
- Achieving Lightning-Fast Performance in your Logical Data Warehouse - November 6, 2017