Data Virtualization and Graph Databases
A couple of years ago now, Forrester forecasted that by 2017 over 25 percent of enterprises would be using graph databases (Enterprise DBMS, Q1 2014. Forrester Research. 2-13-14) . It’s obviously not easy to measure where we are at in terms of adoption today, and even more difficult to know how much of this adoption is in production environments. However, popularity -as in relevance in social networks or presence in professional profiles, frequency of technical discussions or even number of job offers…- can be measured and shows that Graph databases are grabbing a lot of attention.
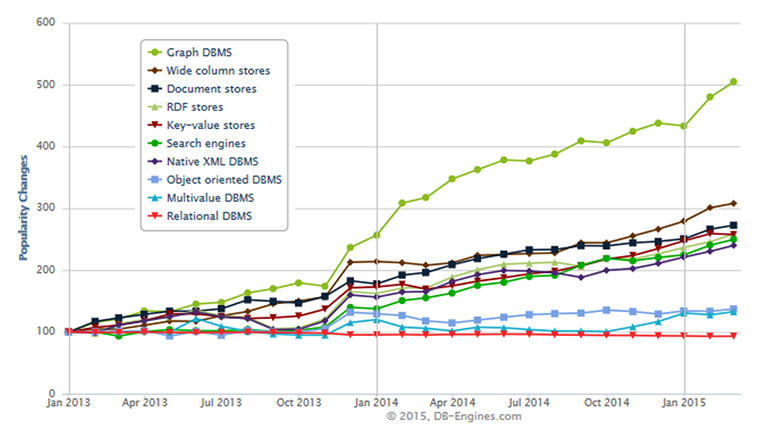
Evolution of Graph Databases from 2013 to 2015 with respect to other alternatives
Actually the relative growth in popularity of Graph Databases over the last couple of years (500% increase) appears to double (Interestingly RDF stores, are in a separate category, which are also graph databases, so the difference should be even bigger.) that of document stores or key-value stores just to name a couple of the “hottest” categories of NoSQL database.
I’m personally a firm believer in the pertinence of Graph Databases and their potential for advanced analytics in scenarios that model highly interconnected entities where other NoSQL alternatives (and of course relational databases) fall short. And this is not just finding friends of friends in social networks, I’m thinking here of crucial use cases like running complex root cause or impact analysis in multilayer network topologies in Telecommunications, or building effective recommendation engines on rich product taxonomies, to name just a couple. However, my interest in this blog post is not on the type of problems Graph Databases are good at solving but rather in looking at Graph Databases from a data integration point of view. How do they fit in today’s data ecosystem? How easily can they be integrated in your current BI architecture? And in this context, how can Data Virtualization leverage the value in Graph DBs?
If you’ve experienced the power of Graph Databases in your projects, you probably have also experienced the pain when it comes to exposing graph data to standard BI tools. Or the frustration of seeing groups of users that could benefit from the incredibly rich linked data in your graph, struggling to use it beyond its initial purpose. How often do Graph Databases end up becoming data silos only accessible to graph savvy IT developers?
And how can Data Virtualization help here? The short answer is precisely by virtualizing your graph, which could be described as applying effective schema-on-read on it. Data virtualization provides a level of abstraction on top of your Graph Database and hides the details of your specific implementation. The BI tools or the consumer application or process does not really need to know if the graph needs to be queried via SPARQL or Cypher or MQL . Or whether it needs to be traversed using Tinkerpop’s Gremlin or another HTTP Rest API. Data Virtualization enables agile integration of your graph data with the rest of your enterprise data assets whether they are internal (EDWH, transactional DBs) or external (cloud app data, public web, etc), structured or unstructured… to effectively realize the notion of polyglot persistence both in informational and operational scenarios. It also promotes repurposing of graph data as well as reuse of access and integration logic in an incremental and explicit way.
What follows are four scenarios where Data Virtualization can add value -or should I better say: where Data Virtualization enables you to get all the value out of your Graph Database-.
Agile BI on graph data (plus other enterprise data): Data virtualization enables easy and on-demand delivery of graph data to standard BI and analytics tools (real time), eventually integrated and enriched with other enterprise data sources or even external or cloud sources and saves you from having to kick off an IT project every time there is a reporting or analytics requirement from the business that involves graph data. I’m sure you could do with less unneeded data replication, with less ungoverned and out of sync copies of portions of your graph.
Fine grained (integrated) security over graph data: Fine grained data access control is not one of the strongest points of existing Graph Databases in the market but Data virtualization can overlay a rich role-based access control model on top of your graph data aligning it in terms of security capabilities with with relational databases: type (category) based access control, resource/node/individual based, property based, etc.
Unified view of multiple graphs: Graph data is a reality, whether it’s your own data in in your own data center (in an RDF triple store , in Neo4J , MarkLogic or Titan DB ) or external data (in Google’s Knowledge Graph , Facebook’s Graph or any public SPARQL endpoint). Thanks to its extended relational model, Denodo can offer an elegant solution to the specific integration case of offering a single unified virtual view of multiple (multi-vendor, multi-paradigm) graph data.
Graph driven RESTful endpoint: Denodo data Virtualization platform enables the provision of integrated (virtualized) data through a REST interface offering a navigational interface that can be driven by Graph Data using an existing Graph Database as the master source of data and enriching it with other enterprise NoGraph (as in Not only Graph) data sources.
This is just a few chosen scenarios, but Data virtualization can also help in others like loading data into Graph DBMS (batch or transactional modes) or in prototyping data graphs. Watch this space for more details and examples of how Data Virtualization leverages the value in Graph Databases.
Interested in learning more on this topic? Check out “Graph Databases from a Data Integration Perspective” by Paul Moxon featured in TDWI BI August 18, 2015.
- Thinking outside the Graph: Data Virtualization and Graph Databases - August 26, 2015