
The volume of data, both structured and unstructured, continues to grow exponentially, and organizations continue to struggle to leverage all of the data to make the best business decisions.
The usual solution, until a few years ago, was to set up extract, transform, and load (ETL) processes to move the data from disparate sources into a single, consolidated data warehouse. However, setting up such processes takes time and effort, so companies have no way to get an immediate business view of their data.
Though there are several scalable approaches to creating a data warehouse, there is still no fast way to make it happen, and this impacts organizations in terms of agility and time-to-market.
With data lakes, which were introduced a few years ago, structured and unstructured data is first stored in a massive, indiscriminate manner, and then processed, considering only the relevant data required for the analysis.
However, within both data warehouses and data lakes, different departments within a business have been establishing data silos, making it challenging to implement data governance and perform data integration, tarnishing the quality of the analytical insights that generated from them.
What we need is a technology that enables seamless data integration of data, offering the possibility of gaining insights and information in the most agile, flexible, and cost-efficient way. Such a technology exists, and it is called data virtualization.
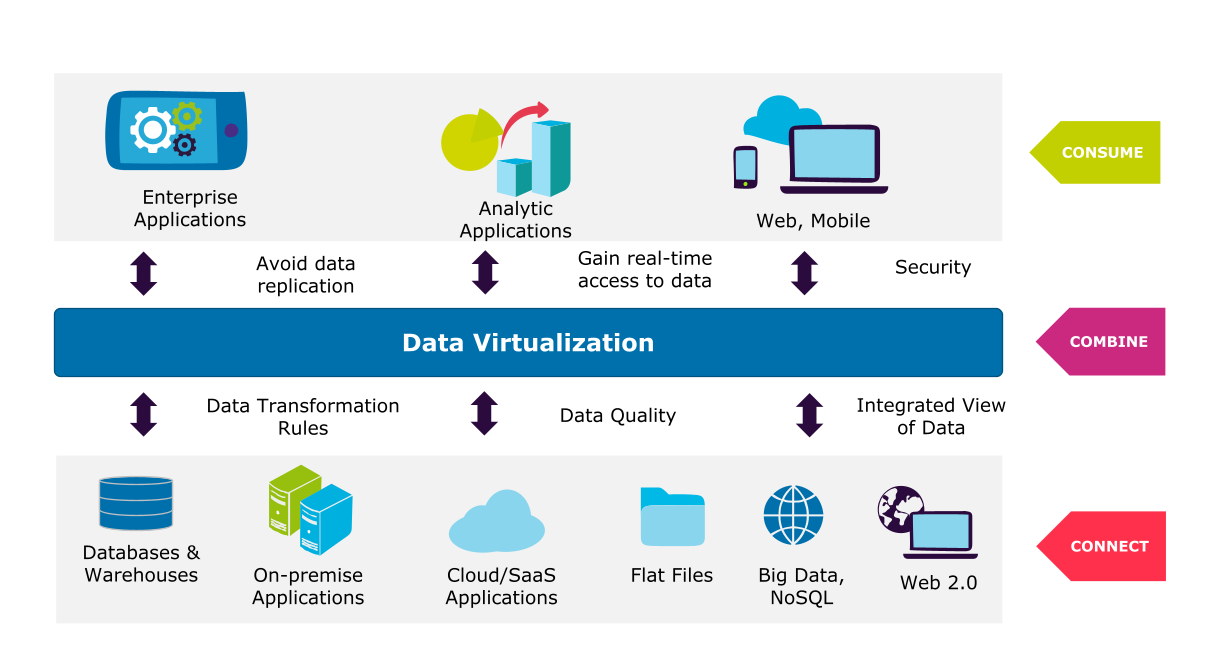
Data virtualization eliminates the need for physical data replication through an intermediate logical layer that virtually integrates data regardless of its location and format. It enables business stakeholders to define their own semantic models and maintains the traceability of data from its point of origin, including all transformations and definitions.
This is what distinguishes data virtualization from data warehouses and data lakes:
- Flexibility: Data virtualization can be implemented in both hybrid and cloud environments, and it does not require costly infrastructure investments.
- Data abstraction: Data consumers can access data without needing to know or understand the underlying complexities, such as data location, format, or structure.
- No data replication: Unlike ETL processes, data virtualization does not need to replicate data into a separate repository, just to transform it to the target format, as data virtualization performs transformation and aggregation on-the-fly.
- Real-time delivery: Because data virtualization connects to the underlying data sources in real time, it delivers fully up-to-date data.
- Agility and simplicity: Data virtualization provides agility when adding, removing, or changing the underlying sources.
Capgemini has chosen the Denodo Platform as the solution to deliver on our promise of value in relation to data virtualization initiatives. Please contact us to learn more.
