
Having advanced caching mechanisms is a key capability of an enterprise-class Data Virtualization platform. Cache in a data virtualization environment is used in different situations:
- Protect the data source from excessive loads or spikes of queries
- Avoid performing complex and/or costly calculations multiple times
- Access sources with a high latency, typically SaaS.
In this post we will illustrate the latter point: how caching, combined with all the other optimization features of Denodo, can be used to optimize hybrid analytic scenarios involving high latency data sources. For that, we will continue the example developed in the previous post of this series.
In that previous post we showed how a data virtualization system can achieve very good performance when it has to deal with large and distributed data sets, thanks to the query optimizer and the use of massive parallel processing (MPP) systems.
Let’s make a quick summary about the business scenario:
The use case consists of a retailer company that stores the information about its 10 million customers in a CRM, and the information about the sales in two different systems:
- An enterprise data warehouse (EDW) containing sales from the current year (290 million rows) and,
- a Hadoop system containing sales data from previous years (3 billion rows).
Let’s say that we want to obtain the total sales by customer name in the last two years.
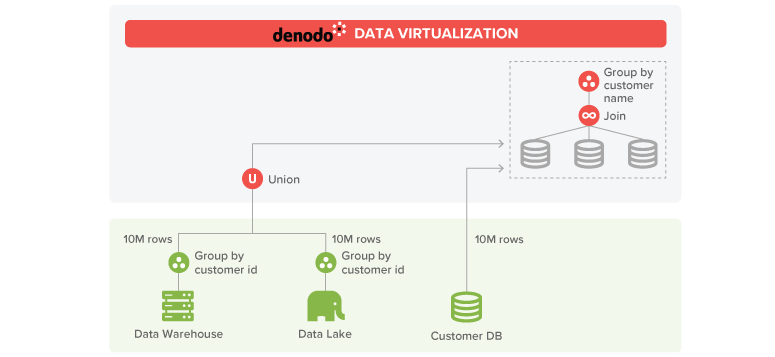
As explained in the previous post, we have a MPP system running on a cluster connected to Denodo through a high-speed network. When the optimizer detects that Denodo will need to perform costly operations on large amounts of data, it can decide to stream the data directly to the cluster to perform them using massive parallel processing.
In our example Denodo first applies the partial aggregation pushdown optimization to drastically reduce the network traffic, retrieving 10M rows from each source (the total sales by customer in each period from each data source) and the customer data.
After that, Denodo can transfer the customer data (10M) and the partial sales aggregations results (10M each) to the MPP cluster and resolve there the join and group by operations to obtain the final result. With this option, the join and group by operations will be much faster as each node of the cluster will work in parallel over a subset of the data.
In a scenario like this, it is common to retrieve some of the customer information from an external system. Let’s say that our report requires for some customers several fields that exist in a CRM on the cloud (for example, Salesforce). In this case, approximately 10% of the customers have information retrieved from salesforce (1 million customers). The query now looks like:
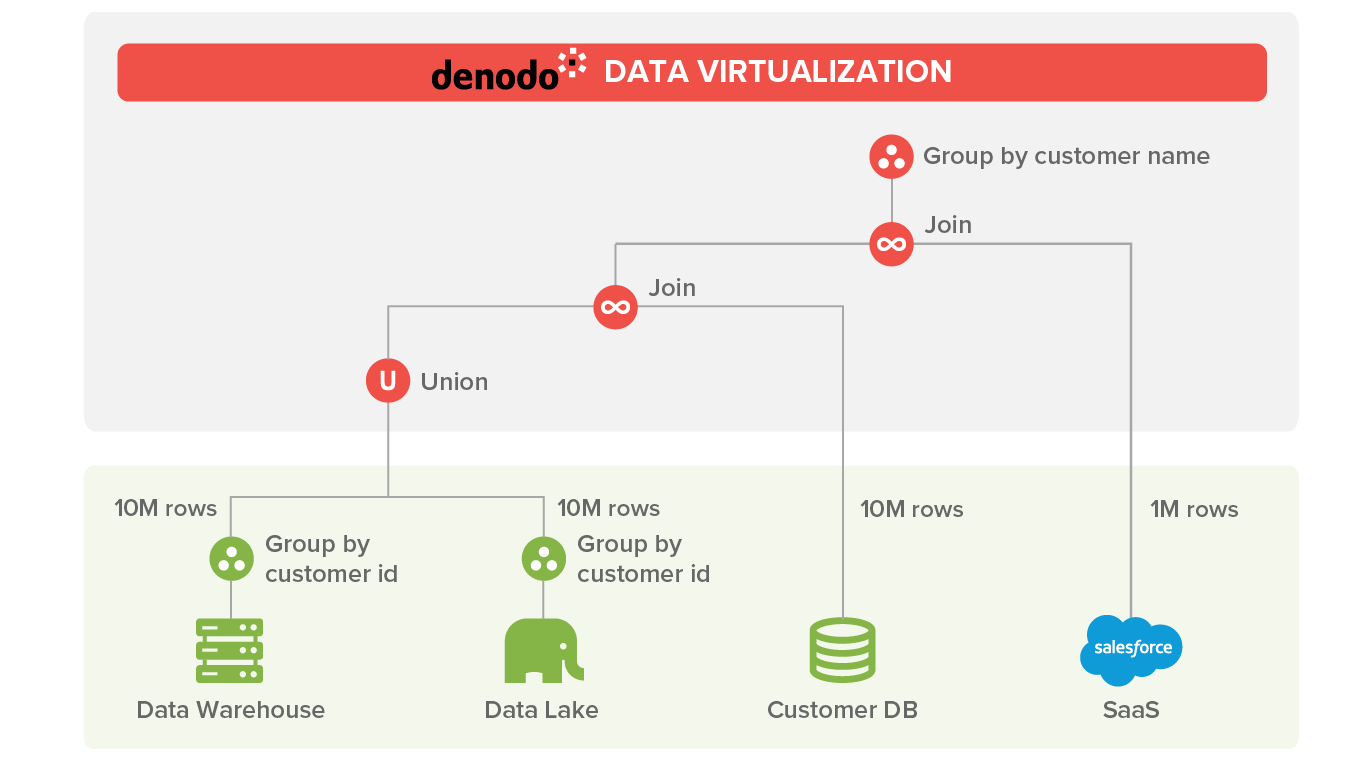
The upper join with the rows coming from Salesforce causes a slowdown in the query because it needs to retrieve the 1M rows of customer information and transfer it through a WAN network. The left branch of the join will be ready before all customer data is retrieved from the SaaS data source.
This situation can be avoided if the customer data is cached in the MPP system. Having data sets cached on the MPP system has several advantages, some of them listed below:
Queries involving these data sets can avoid the step of moving the data to the MPP on each query.
Combinations involving those cached data sets take full advantage of the parallel architecture.
These systems provide highly efficient bulk load mechanisms so there are no drawbacks when using them as a cache system.
With the Salesforce data cached in the MPP system, the optimizer chooses a execution plan where it moves the aggregations from both union branches and the on-premises customer information to the MPP and the query is resolved there, sending the results back to Denodo. With the help of the parallel architecture the time of the query is almost the same as if the SasS source was not included in the query.
In the next post of this series we will provide execution times of scenarios like the one described here using Denodo 7 to illustrate how all these query optimizations work together to achieve an excellent performance.