
In the previous article we reviewed some of the pros and cons behind the data lake ideas, as well as the reasons why a logical architecture like the virtual data lake addresses some of those issues. In this section, we will review the architectural elements of the virtual data lake, and will dig deeper into its technical implications.
Architecturally speaking, a virtual data lake has two core components:
- A physical data lake, usually based on a modern SQL-on-Hadoop system like Spark. The lake provides the main storage area and execution muscle for analytics, machine learning, etc. Other approaches are also possible, for example, implementations with cloud data warehouses like Snowflake or Redshift are becoming popular. This article will focus on SQL-on-Hadoop systems.
- An advanced virtual layer like Denodo, that provides a façade to end users, abstracts the nature of the original sources, and orchestrates execution based on the decisions of its optimizer
These two core components are complemented by:
- Other Data Sources, that store the additional data. These sources can be:
- Data Warehouse: in most companies, the data warehouse still plays a crucial role in the data landscape. Access to the warehouse data from the data lake will be a key tenet of this architecture
- Internal Sources: other on-prem databases, packaged application, SAP, documents, etc.
- External Sources: SaaS vendors, social media, open data, etc.
- Streaming: In a modern lambda architecture, typical of IoT ecosystems, some of your sources will not have storage, but will rather produce streams of data. Sensors and devices, for example. In this case, you will need some ingestion pipeline, that captures the data, keeps it in a buffer, potentially applies some transformations, and eventually lands it in the lake. Kafka and Spark Streamings are common players in this area.
- Consuming applications that serve the end users, ranging from BI and analytics (Tableau, Power BI, Microstrategy, etc.), data science (Zeppelin notebooks, Python libs, R, etc.) and end user applications (portals, dashboards, websites, mobile, etc.)
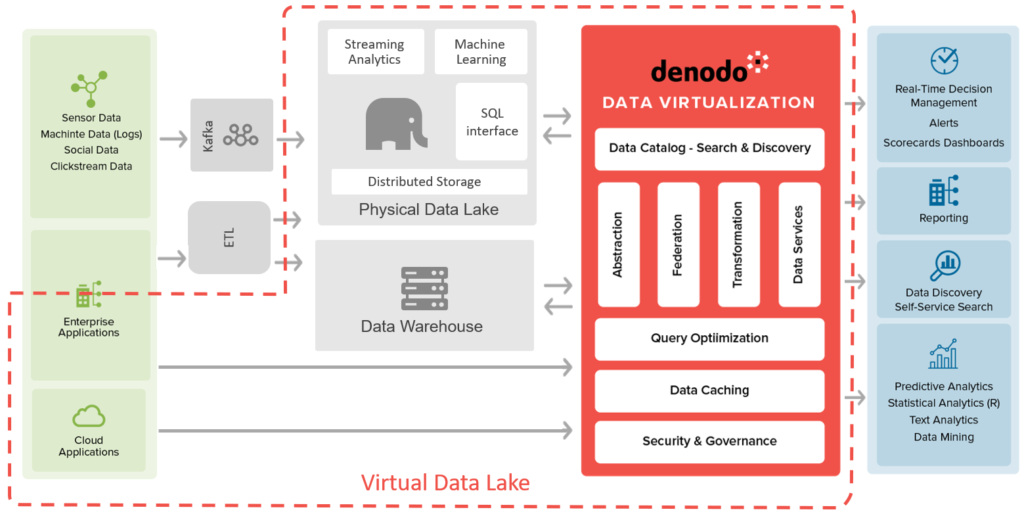
A typical virtual data lake architecture
Let’s analyze this architecture more in detail to understand how the virtual layer interacts with these components:
- Physical lake as a data source: The most obvious interaction in this architecture is the connection of the data lake as a core data source for the virtual layer. All tables in the lake are accessible through the virtual layer. Queries that involve data in the data lake are completely pushed down to the lake engine, so in those cases the query execution happens completely in the lake cluster and the performance is equivalent to the physical architecture
- Other sources: Other data assets that are not in the lake are also connected to the virtual layer, so that their data is available through a single layer to end users. The virtual layer allows for federated queries that combine, on demand, data native to the lake with external data sources
- Physical lake as storage & cache: Although Denodo does not have any storage per se, it can persist data in its cache system. Since the same physical lake can be configured as the cache system, this means that any cached view will automatically become part of the lake. In a similar fashion, Denodo can also create temporary tables and materialized views in the lake. From that perspective, Denodo can act as a way to efficiently ingest any data into the lake and persist the results of in-lake processing for future use. Denodo automatically creates the tables based on the source structure and data types, and uploads content to HDFS, Amazon S3 or Azure Blob Storage using Parquet compressed with Snappy.
- Physical lake as an execution engine: In this context, Denodo’s Cost Based Optimizer (CBO) can decide to use the execution engine of the lake even for queries involving data that is not in the lake. This decision is automatically taken by Denodo’s optimizer based on an analysis of the queries and data volumes. It can also be enabled manually, through a hint. When it’s used, Denodo temporarily moves certain data on-demand to the lake to execute there some stages of the processing pipeline that can take advantage of its MPP architecture. This technique can lead to surprisingly fast execution for federated queries.
- Virtual layer as the security layer: When the data in the lake is exposed to different types of users, not just data scientists, securing access becomes an important part of the virtual layer, that acts as the single point of entry. Data virtualization tools provide a rich security layer, similar to a traditional database, that allow for role-based access control to the different tables, views, rows and columns.
In most virtual data lake scenarios, these five items work together, with the Denodo engine orchestrating the executions behind the scenes. For more details on the technical implications of the execution engine, check out this article where Paula Santos, one of our core developers, explains in detail how the optimizer works with large data volumes.
Check out my next post in the series: “The Virtual Data Lake for a Data Scientist“

- Improving the Accuracy of LLM-Based Text-to-SQL Generation with a Semantic Layer in the Denodo Platform - May 23, 2024
- Denodo Joins Forces with Presto - June 22, 2023
- Build a cost-efficient data lake strategy with The Denodo Platform - November 25, 2021
This is a research-only question. One thing I remain unclear on with regards to the Virtualization architecture posted here is that it has a physical data lake, and yet one of the guiding principles of Virtualization would appear to avoid the movement of data into things like data lakes.
So are you simply talking about physical lakes and warehouses that already exist becoming datasources – and not the creation of new ones as part of the virtualization architecture?
If, for example, there are no or few existing lakes/warehouses, would you expect Virtualization to be almost entirely federated?
I say ‘almost’ as there could still be [legacy] systems unable to support federated queries that might need to have their data go into a lake just to make it accessible.