
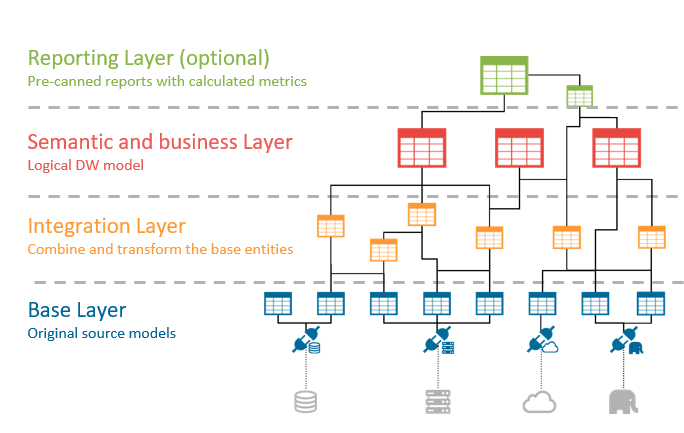
One of the most common deployments of the Denodo Platform in organizations across the globe is serving as a semantic layer that simplifies data consumption to increase self-service for business users. Three core ideas, working together, enable that scenario:
- The data virtualization core abstracts the data sources to offer a common access point. This way, end users do not have to deal with the complexities of multiple connections, different protocols, drivers, API calls, and other technicalities that stand in their way. Access to data is just a click away.
- Semantic views are often used to simplify usage even further, denormalizing content, eliminating unnecessary columns, pre-creating common transformations, or even defining pre-canned report views with common metrics. This layer-based approach is a common best-practice to increase reusability.
The Denodo Data Catalog provides an extra layer of documentation, governance, classification, and data query wizards, which add additional context to enable business users to better understand their data.
The use of a semantic layer is a well established practice. However, in this era of generative AI (GenAI), we at Denodo were also wondering if it can enhance the text-to-SQL capabilities commonly provided by large language models (LLMs). Can the features that facilitate data usage for business users have an impact on the success rate of generative AI models? This question is not just theoretical. Text-to-SQL generation is at the core of very popular patterns for GenAI applications (like retrieval augmented generation, or RAG), and a critical piece of next-generation data management tools and customer service chatbots. So we wanted to design a test for measuring the accuracy of text-to-SQL generation, enabled by a semantic layer built with the Denodo Platform.
Designing the Test
Recent studies have shown that additional semantics can have a very significant impact on text-to-SQL accuracy. And given the importance of text-to-SQL capabilities, there are already a few benchmarks designed to assess the effectiveness of text-to-SQL generation. In particular, BIRD (https://bird-bench.github.io/) and Spider (https://yale-lily.github.io/spider) offer a solid foundation for analyzing this topic. Both benchmarks provide a set of databases and tables, natural language questions, and the correct SQL queries that answer each question.
These benchmarks are quite extensive. BIRD has around 12,000 queries and Spider has around 10,000. For this study we choose a representative subset of questions from each test.
|
Benchmark |
# DBs |
# Tables |
|
BIRD Dev dataset |
11 |
75 |
|
Spider |
200 |
1020 |
Even though the chosen subset of questions did not require all the tables and schemas, we still loaded the full datasets to accurately represent the complexity of choosing the right database and tables for each question. This is not part of the benchmarks, where the text-to-SQL accuracy is only tested in the scope of a single database. However, in the context of the use cases relevant to the Denodo Platform, we consider this initial table resolution problem to be a critical piece. When an end user approaches the Denodo logical layer with a question, we cannot expect them to know which exact database or schema contains the relevant information. Therefore, the semantic search may span thousands of tables and views. Choosing the right tables for a query across thousands of them is one of the most complex parts of the process, and it is very relevant within the scope of Denodo Platform usage, so we wanted to incorporate it into our tests.
Finally, we used the following components for the rest of the environment:
- LLM: OpenAI GPT-4 Turbo
- Embeddings model: Open AI text-embedding-3-large
- Vector database: OpenSearch 2.13
- Denodo Platform 9.0 beta
Bringing the Semantics
We wanted to simulate a use case in which an organization leverages the Denodo Platform for business self-service. As such, we wanted to replicate some of the common patterns found in those scenarios, like a layered data modeling approach, and proper documentation in the Denodo Data Catalog.
For that, we added descriptions to all datasets, automatically generated using the LLM. This is a capability that is coming in the next Denodo Platform release. We also included descriptions for the columns. In the case of BIRD, we added the contextual information that is part of the test definition for each corresponding column. For Spider, we manually added descriptions for the columns of the tables.
We also created some derived views, denormalizing schemas (e.g., we created a “fat” table that joins fact with dimensions) and joining related tables or hierarchies together, generally following common practices for self-service deployments. We also defined associations across tables with PK-FK relationships.
The Denodo Platform offers additional metadata and semantic information, like business categories, tags, and endorsement messages, but that information was not used for this test.
Running the Benchmark
For a baseline, we first ran the tests based on the table information only (schema name, table name, column name, and data types).
For the execution with the Denodo Platform, we included additional information directly available in the Denodo Platform today:
- Table and column descriptions
- Associations across tables
- Profiled data samples
- Additional derived views built on top of the original data models
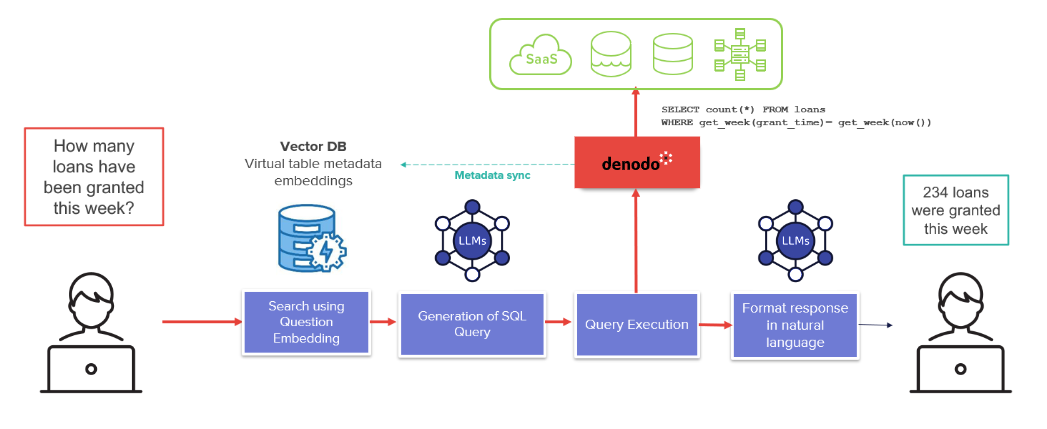
In both tests, we followed the same execution flow:
- Vectorize and index the metadata in OpenSearch. This process was done ahead of time.
- Prompt the LLM with some guidelines on Denodo’s SQL dialect, to minimize syntax errors.
- Identify the schemas and tables relevant to the question using the question embeddings in a vectorized search across the entire set of tables. This is a complex process, involving more than a thousand possible tables in the case of Spider. We implemented a customized advanced table resolution model to address this challenge.
- Ask the LLM to build a SQL statement based on the results from the search and a series of prompts that we built following a chain of thought pattern.
The additional semantic information provided in the derived views, descriptions, and data profiles are the only differences between the two tests, and any difference in results can be easily attributed to those additions.
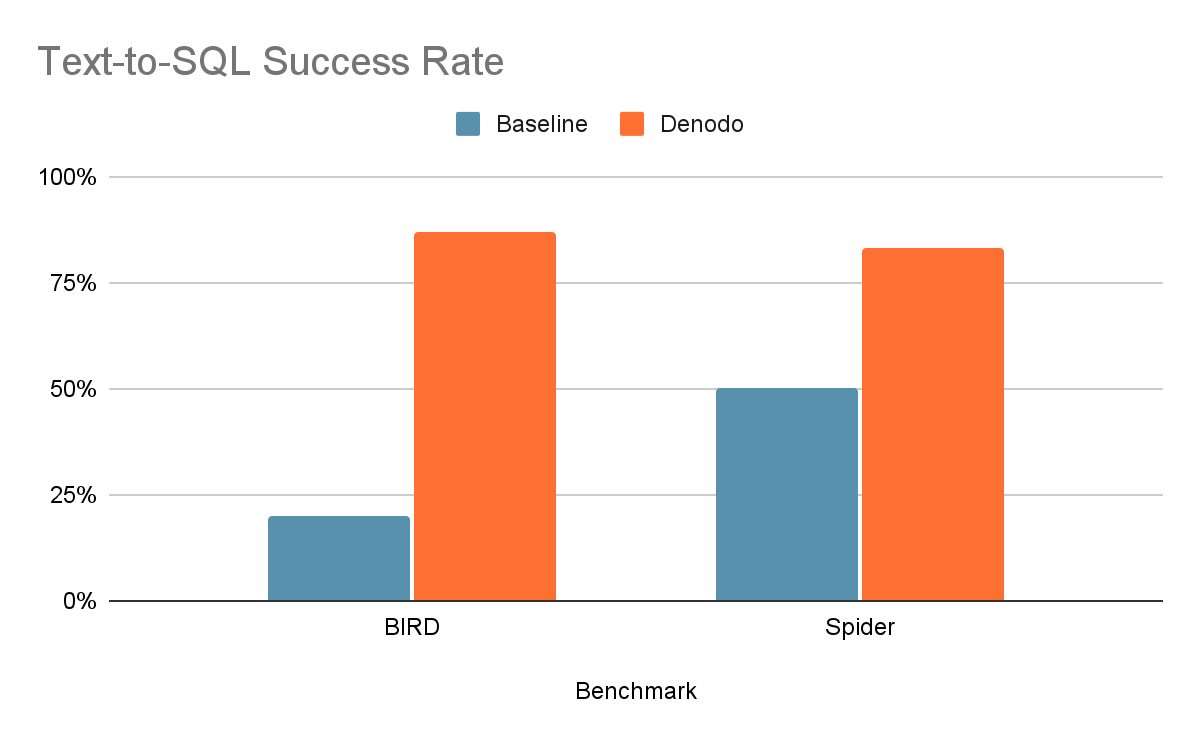
As displayed in the table and chart below, the results were quite impressive:
|
Benchmark |
Success Rate |
|
|
Baseline |
Denodo |
|
|
BIRD |
20% |
87% |
|
Spider |
50% |
83% |
Understanding the Results
Why is that additional information so important for the accuracy of results? Let’s try to understand the answer by looking at a couple of examples:
Example #1: Find the make and production time of the cars that were produced in the earliest year?
|
Baseline (Incorrect) |
Denodo (Correct) |
|
SELECT c.make, v.build_year FROM spider_master.vehicle_driver_vehicle v JOIN spider_master.car_1_car_names c ON v.model = c.model WHERE v.build_year = ( SELECT MIN(build_year) FROM spider_master.vehicle_driver_vehicle ) |
SELECT make, year FROM spider_master.car_1_cars_data_dv WHERE year = ( SELECT MIN(year) FROM spider_master.car_1_cars_data_dv ) |
In this case, the baseline example fails to choose the correct tables and join conditions. However, the Denodo Platform semantic view “car_1_cars_data_dv” is chosen, which includes the join of those tables, and a simpler, correct query is generated.
Example #2: What are the websites for all the partially virtual chartered schools located in San Joaquin?
|
Baseline (Incorrect) |
Denodo (Correct) |
|
SELECT website FROM bird_master.california_schools_schools WHERE county = ‘San Joaquin’ AND charter = 1 AND virtual = ‘partially virtual’ |
SELECT website FROM bird_master.california_schools_dv WHERE county = ‘San Joaquin’ AND charter = 1 AND virtual = ‘P’ |
The baseline case makes a wrong assumption in which the filter value for virtual, a text field, is set as virtual = ‘partially virtual’.
With the Denodo Platform, based on the sample values, the test is able to infer the correct filter (virtual = ‘P’) and produce the correct results. This type of columns with flags and codes are very common in analytics, and without proper documentation and examples it is impossible for the LLM to generate the right answers.
The Benefits of the Denodo Platform for Enterprise RAG
As described here, the use of the Denodo Platform, together with an LLM, can significantly improve SQL generation accuracy, reducing model hallucination and minimizing untrustworthy responses. Built-in features designed to bring data democratization and simplify the usage by business users are also a great companion for an LLM in RAG and text-to-SQL pipelines. We’ve also observed that LLMs struggle with complex queries involving many JOINs and source optimized SQLs, similar to how a non-technical user operates. The Denodo Platform can expose “AI-friendly” data views to GenAI apps that simplify the original schemas and help improve the accuracy of SQL generation.
From a broader perspective, a common access layer like that provided by the Denodo Platform also simplifies access to corporate knowledge from GenAI applications. This knowledge is often dispersed across a variety of data sources and applications, and it usually needs to be retrieved in real time. Think, for example, of the amount in your bank account, or the location of a package you are tracking. By integrating the Denodo Platform’s logical data fabric and data virtualization technology, companies can provide LLMs with a unified, secure access point to query all enterprise data in real time, while maintaining the data lineage for transparency on the data origins. The Denodo Platform is also able to enforce user-based security for each answer, in a consistent manner, across the entire data landscape, which enables specific results per user, such as masking certain PII information.
These broader benefits have already been discussed in other articles, but are nonetheless also relevant in text-to-SQL analysis, as the complexity of the problem grows exponentially if the GenAI application needs to craft queries to multiple backend systems with different standards and dialects.
A common access layer enabled by the Denodo Platform can be crucial in developing GenAI applications, as it bridges the gap between LLMs and organizational knowledge.

- Improving the Accuracy of LLM-Based Text-to-SQL Generation with a Semantic Layer in the Denodo Platform - May 23, 2024
- Denodo Joins Forces with Presto - June 22, 2023
- Build a cost-efficient data lake strategy with The Denodo Platform - November 25, 2021