
In the previous article we reviewed the architectural elements of the virtual data lake, and will discuss why a virtual data lake can play a key role for the data scientist. In this post, we will review why it plays a key role for the business user.
The concept of a data lake is very often only associated with data scientists. And there is no doubt that the data science community has benefited tremendously from the the evolution of the data lake architecture. However, a multi-purpose data lake can improve the ROI of the investment. When architected properly, a data lake can be used by a broader audience, extending the benefits of the lake to other users. In addition, it creates a natural channel for data scientist to share their findings.
This type of data lake usually involves the definition of different zones, starting with raw data (landing zone) that evolves until it reaches the production zone. Different types of users can take advantage of data in different zones. For example, a data scientist will find the raw data extremely useful, while the BI analyst would use the production area, more organized and curated, to create reports and dashboards.
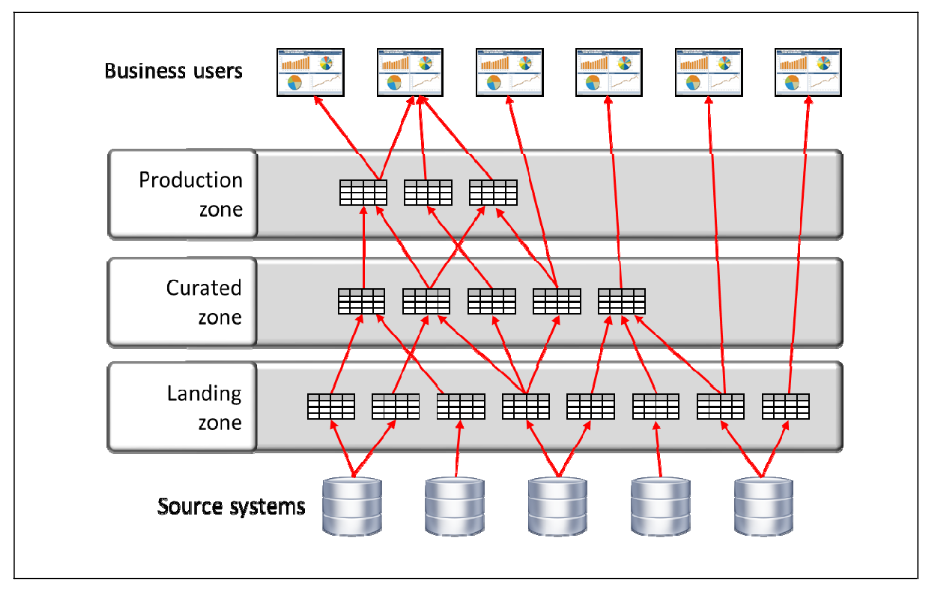
From the perspective of a data scientist, these different zones match pretty well the different steps in their typical workflow, described in the previous article of the series. Making that data available to other users just involves some discipline and procedures for the “promotion” between zones.
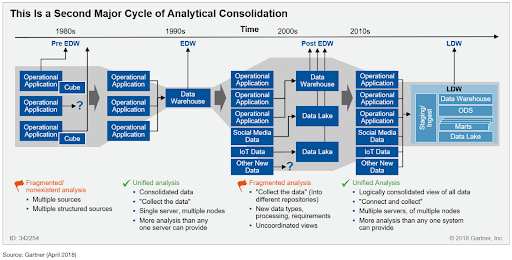
Like in the case of the data scientists, the combination with a virtual layer can yield multiple advantages. From the perspective of a business users, we are not exposing the data lake alone, but a broader combination of other sources. The EDW is usually a key piece. These types of architectures have been explored in detail by industry analysts, for example in the publication by Henry Cook from Gartner (April 2018) Adopt the Logical Data Warehouse Architecture to Meet Your Modern Analytical Needs, that sees the logical approach as the natural evolution of the modern analytical architectures.
Let’s review more in detail the benefits of the logical architecture for a business user:
-
- Access to all corporate data. Reports often need data from other locations that are not available in the lake. Even in companies where is common policy is to move as much data as possible into the lake, there are many exceptions to the rule:
- Need for real time data. Real time dashboards will find that lake data hours or days old. Virtualization opens the door to real time data through the same layer.
- Usage of cloud sources and SaaS providers. A special case for the real-time data sources. Access to the live status of an ongoing marketing campaign can only be achieved with live queries to the REST API. Denodo offers SQL access to that information to easily integrate with other data.
- Laws and restrictions. Some regulations prohibit the replication of data or storage outside of a particular region. Virtualization allows access and usage of these data assets within the law.
- Prevalence of existing data warehouses. In most cases the EDW is the official source for reporting metrics. The sheer volume of the EDW and the complexity of their data flows prevent a feasible replication to the lake. From that perspective, the data lake is seen as an addition for data science. In addition, lower grain and historical storage in the lake can add significant additional value, and virtualization can be used as the bridge between the two systems
- Lack of cooperation between departments. In many cases data sources are controlled at a departmental level, and other business areas won’t accept uncontrolled replication of their assets
- Access to all corporate data. Reports often need data from other locations that are not available in the lake. Even in companies where is common policy is to move as much data as possible into the lake, there are many exceptions to the rule:
- Decoupling back-end technology from reports. With the constant evolution of Big Data technologies, it is quite common that the system used for the physically data lake changes. Switching Hadoop vendor, replacing Hive with Spark, or moving to a cloud offering like EMR or Databricks are common cases. The use of a virtual layer isolates these changes from the consumers that are connected through the virtual layer instead of a direct connection to the physical lake.
- Business friendly data model. Back-end data structures are not always optimal for user consumption. Hyper-normalized star-schemas from the warehouse and numerical tables generated as a result of a machine learning process are hard to digest for non-technical users. Data virtualization allows you to decouple the models you present with the way data it is stored.
-
- You can present data in a shape tailored to a particular set of users, without the need to create a new replica or data mart. This concept aligns very well with the idea of multi-zones explained above.
- The semantics of this model are not tied to a specific report or visualization tool, they are available for all through the virtual layer. Tools like Tableau, PowerBI, Cognos, Microstrategy, etc. can all use the models defined in Denodo.
- Denodo’s Data Catalog surfaces the metadata in an user friendly way. Data is not a black box. It comes with lineage, descriptions, tags and categories, and it is searchable.
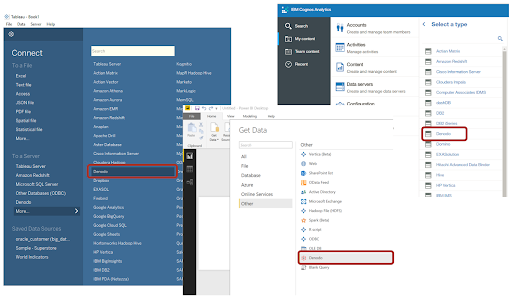
Most reporting tools offer an out-of-the-box adapter for Denodo
- Flexibility in delivery. Denodo doesn’t only provide SQL-based access. The same data models (and security settings) are exposed through RESTful and OData services. No extra coding involved. This may be an interesting solution for custom web applications, mobile apps, and integration with third-party tools. For example, you can enrich your Salesforce reporting with data served by Denodo via Salesforce Lightning Connect.
- Security. Although data scientists usually enjoy a high degree of freedom in terms of data access control, dashboards and reports are normally more regulated. Different user groups should be able to see only certain pieces of information. These restrictions translate into privileges for schemas, tables or even rows and columns with masking rules.
- Denodo allows you to provide complex access control on all kinds of data sources, even when the source does not provide that support. This is especially important in the context of data lakes, since technologies like Spark or Presto do not offer yet the granular control expected from a traditional database.
- The virtual layer can provide that tighter control that will help broaden the consumer base
Conclusions
Data lakes are still a novel concept, and data scientists usually work with a degree of freedom that traditional EDW users never had. Yet sharing the results of their work to incorporate into traditional reporting and dashboards is a key aspect of a profitable data lake. As we have seen in this article, Data virtualization can help contextualize the data generated by the data science processes and make it available to broader base of business users. And it does it in a way that is easy to digest, controlled and secure.
Industry analysts see logical architectures as the natural evolution of the analytical ecosystem. Logical architectures are able to consolidate and unify access to the fragmented ecosystem created by the modern needs of data science, traditional data warehousing and ubiquitous usage of hosted cloud applications.
Check out my previous articles in my data lake series:
- Rethinking the Data Lake with Data Virtualization
- Architecting a Virtual Data Lake
- The Virtual Data Lake for a Data Scientist

- Improving the Accuracy of LLM-Based Text-to-SQL Generation with a Semantic Layer in the Denodo Platform - May 23, 2024
- Denodo Joins Forces with Presto - June 22, 2023
- Build a cost-efficient data lake strategy with The Denodo Platform - November 25, 2021