
Use Cases for Data Virtualization in the Cloud
As more and more enterprise data moves to the cloud, it has become necessary for data integration initiatives to think past the earth-bound data center, where all enterprise data has been living cozily until now. Data sources have gradually moved to the cloud, far away from the enterprise data center. For businesses that are looking for vital insights and building applications for transactional commerce, information retrieval involves the meaningful integration of both on premise and cloud data. Data virtualization offers advanced features to not only access a wide array of data sources, both on premise and cloud, but also to combine data from both kinds of sources and make it available to business users in real time, or near real time.
The standard, default operation is for a data virtualization server to combine the on premise and cloud data transparently for consuming client applications. However, accessing data from the cloud presents some security and performance issues related to circumventing the firewall around the sources safely and the need to transfer high volumes of data across the network. Data typically travels more slowly between far away sources than it does within the data center. Some data virtualization products offer advanced query optimization features that can help to reduce the volume of data that needs to traverse the network. However, sometimes query optimization does not produce the desired results and it is necessary to transfer a high volume of data through the network to answer queries.
Use Case 1: The Cloud Logical Data Warehouse
More and more businesses looking to tame the onslaught of data-gone-wild are turning to a logical architecture that abstracts the inherent complexities of big data using a combined approach of data virtualization, metadata management, and distributed processing. The logical data warehouse architecture combines all three, as well as all of the capabilities of the monolithic enterprise data warehouse.
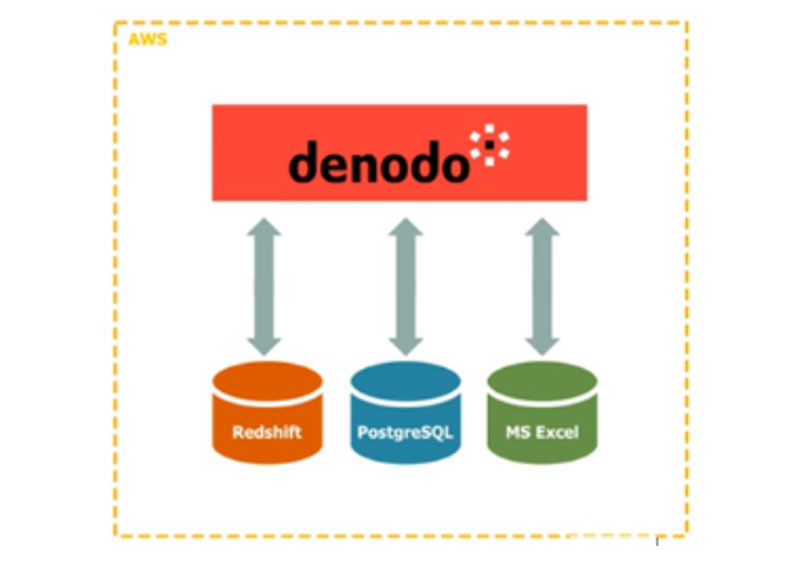
A fully cloud-native data warehouse such as Amazon Redshift, for example, can be extended through integration with other data sources such as a traditional database (e.g. PostgreSQL), flat files, XL files, SaaS applications (e.g. Salesforce), and/or Hadoop using data virtualization. The data virtualization server becomes the front end for all of these data sources and aggregates the data in real time for use in client applications. Each data source brings its own inherent capabilities, strengths, and benefits to the cloud logical data warehouse. The data consumers, however, are isolated from all this complexity. They just access the data virtualization server using their preferred access mechanism such as a relational database, JDBC, ODBC, Rest, or SOAP web service.
The following diagram represents an architecture that uses the Denodo Platform for AWS to establish a cloud logical data warehouse.
Use Case 2: The Cloud Gateway
Complexity presents itself as more and more businesses add data sources to the cloud, even while some keep their data sources in the data center. Now the security teams have to ensure that all the connections needed from within the firewall to the cloud are available, secure, and performant. This quickly becomes a many-to-many scenario that is very difficult to manage. Another major challenge is reducing the volume of data traversing the network. Cloud sources are far away from the data center, and here again, minimizing the volume of data transfer is crucial to performance. This is especially true in the case of Hadoop or an enterprise data warehouse that stores huge volumes of data (e.g. Terradata), where it is important to carefully monitor the number of queries that are sent to these sources.
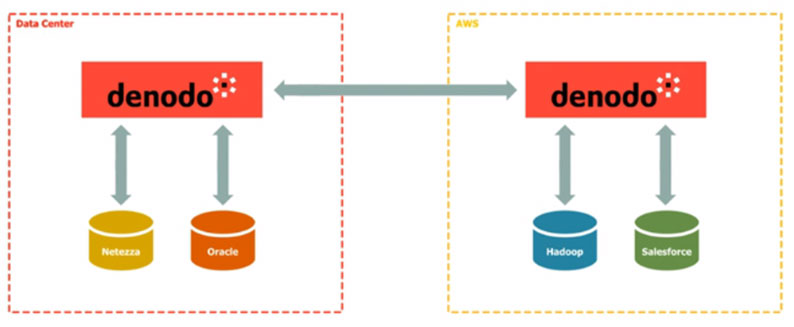
Solution: First, a cloud instance of the data virtualization server deployed close to the cloud sources helps to integrate the data in the cloud. A second, on premise version of the data virtualization server in the data center then helps to integrate the enterprise data assets in the data center. Finally, a bridge that connects the two instances, in which each data virtualization server reads the other as a JDBC source, solves the problem. Data combination happens at two levels – once at the cloud level, and once at the data center level. The result of the combinations of one group is sent over the network to be aggregated with that of the other group. A data communication relay is established between the two environments – the cloud and the data center.
With this type of architecture, the security teams need only worry about securing the two data virtualization server instances. No other firewall exceptions are required, and it is easier to manage and audit than the many point-to-point connections between all clients and sources. Above all, consuming applications have the flexibility of to use the data virtualization server instance that is closer to them.
The following diagram represents an architecture that uses two instances of the Denodo Platform to establish a cloud gateway.
If you have any questions about either use case, please comment below. See our Denodo Platform for AWS data sheet for information about licensing options and deployment procedures.

- Capitalize on the Enterprise Data Services Marketplace - May 24, 2016
- Stop Searching Heaven and Earth for Data - May 9, 2016
- Drinking from the fire hose of Fast Data? - March 21, 2016