
Believe it or not we are now over 25 years into building data warehouses and many companies around the world have very well-established systems supporting query, reporting and analysis of historical master and transaction data that has been captured from their transaction processing systems. This data is captured, cleaned, transformed and integrated into a data warehouse and typically stored in an analytical relational database management system (ARDBMS). Examples of ARDBMSs include Amazon Redshift, IBM PureData System for Analytics, Microsoft SQL Server Analytic Platform System, Oracle Exadata, Snowflake, Teradata, …to name a few.
In addition, subsets of the data in these data warehouses may have been extracted and stored in separate dependent data marts. A typical example is shown in Figure 1 below where a data warehouse is used to analyse sales transactions and includes country specific data marts to support query, reporting and analysis at the individual country level. This kind of set-up is something I have seen on many occasions.
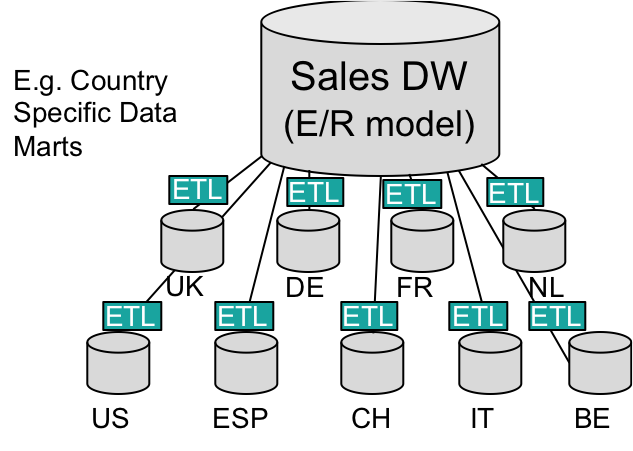
For a lot of companies, the way these systems have been designed is based on classic historical entity/relationship data modelling at the data warehouse level and star schema data modelling at the data mart level. In addition, these systems are now very much considered production systems and are subject to strict change management procedures and processes when changes are required.
While this ‘waterfall approach’ is quite widely practiced, many companies are now realising that this approach to building data warehouses introduces several problems.
These include:
- High total cost of ownership due to the number of physical data warehouse and data mart data stores – i.e. there are too many copies of data.
- Slow and very costly to implement changes to the data warehouse E/R data model because change can impact ETL processes populating the data warehouse and can also result in changes also needing to be made to many dependent data mart data models, their ETL processes and all the BI reports hanging off these data marts.
- Little to no agility because the pace of change can’t keep pace with the demand for new data.
- There can be a risk of inconsistency across DW and marts.
- There is no drill down across marts e.g. to look at sales in Northern Europe.
Given these issues, it is often the case therefore, that many data warehouses have been designated as being in need of modernisation to reduce the impact of change, reduce data copying, fuel agility, simplify access and reduce cost.
There are several ways in which this can be done. They include:
- Moving to the cloud to switch to an operational expenditure subscription model.
- Changing the data warehouse E/R data model to a more modern design that minimises the impact of change e.g. Data Vault 2.0.
- Replacing physical data marts with virtual data marts to reduce data copying.
For many companies, moving to their data warehouse to the cloud as part of a cost cutting exercise is very high on their agenda. Most analytical relational DBMS vendors now offer their DBMS as a Platform-as-a-Service (PaaS) offering on one or multiple different clouds such as AWS, Microsoft Azure, Google Cloud Platform or IBM Cloud.
However, it is rare that they necessarily want to just ‘lift and shift’ an aging data warehouse design when migrating data warehouses to the cloud albeit that ‘lift and shift’ data migration utilities are available. It is increasingly likely that companies want to maximise the benefits of data warehouse modernisation while they are migrating to the cloud but are concerned that they can’t because of the impact. For example, they may want to change the data warehouse design to a Data Vault model while they are migrating. However they are concerned that by doing so, they create more tables in the data warehouse which will result in a need to create more data marts and so more physical data stores will appear. This of course could increase cost. The question is therefore, how can you migrate data warehouses and data marts to the cloud while modernising at the same time to maximise the benefit while minimising the risk?
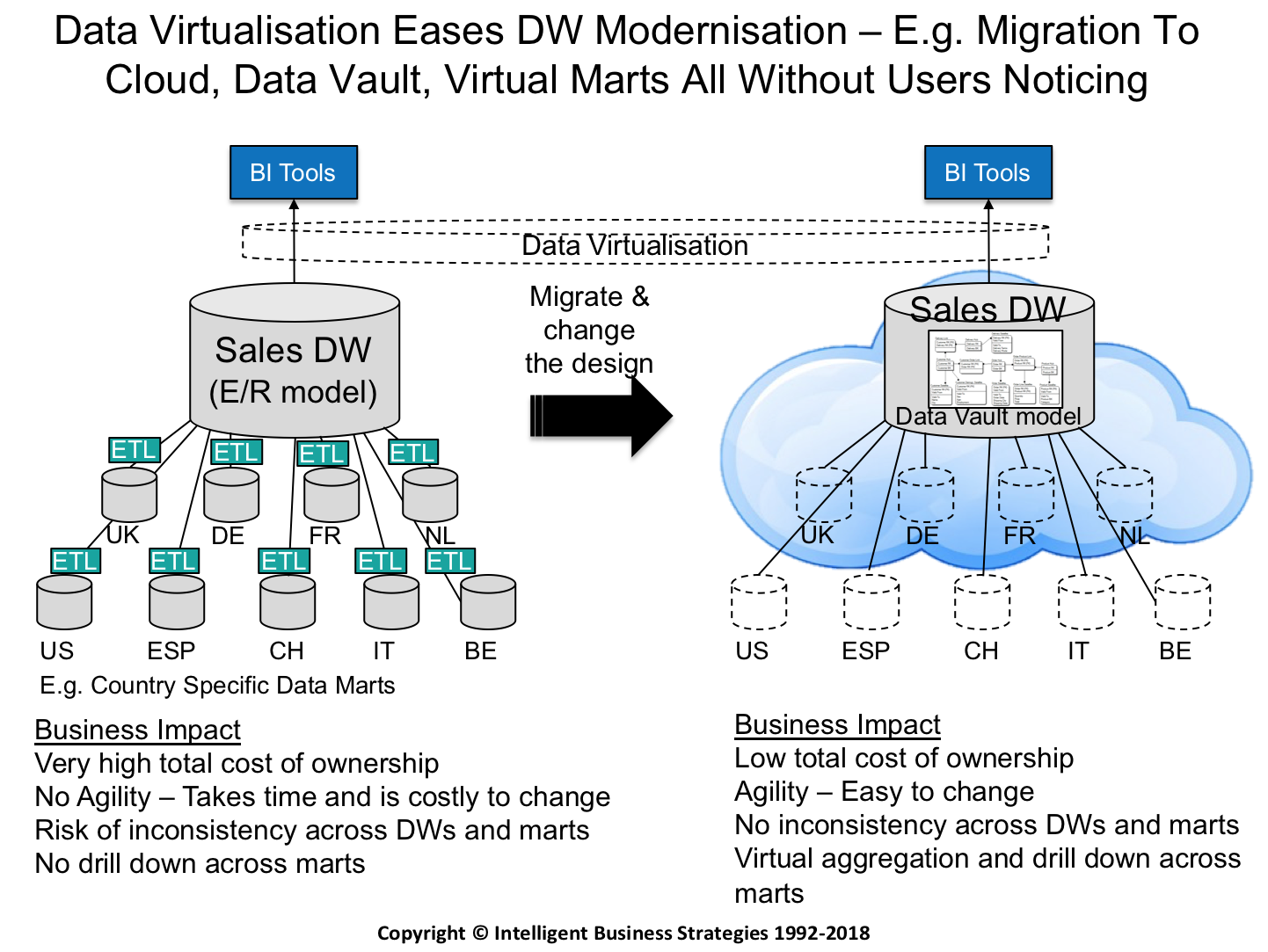
The answer is data virtualisation. Figure 2 below shows how data virtualisation can be:
- Placed between the BI tools and the data warehouse
- Used to replace physical data marts with virtual data marts
This would allow a data vault design to be introduced and physical data marts to be replaced by virtual data marts all potentially without users noticing. The benefits as a result of such modernisation would be to:
- Lower the total cost of ownership by getting rid of data copies and physical data stores.
- Introduce agility by making the data warehouse and data marts easy to change.
- Remove inconsistency across data warehouse and marts.
- Introduce virtual aggregation and drill down across marts to accommodate regional analysis requirements such as Sales in Northern Europe.
There would be an impact on ETL processes populating the data warehouse but the speed in which that is done could be dramatically reduced by using data warehouse automation software in combination with data virtualisation to quickly switch to a data vault design and re-generate ETL jobs rather than re-developing them all by hand. Something well worth considering I think!
Don’t miss any debate-style 3-part Experts Roundtable Series, and watch cloud service providers, systems integrators, and customer organizations duel it out with their insights into the statistics published from Denodo’s 2020 Global Cloud Survey.
- Enabling a Customer Data Platform Using Data Virtualization - August 26, 2021
- Window Shopping for “Business Ready” Data in an Enterprise Data Marketplace - June 6, 2019
- Using Data Virtualisation to Simplify Data Warehouse Migration to the Cloud - November 15, 2018
The data that you’ve shared in this blog is informative. I like the way you present the useful information about cloud migration service providers.