
In the previous article we reviewed the architectural elements of the virtual data lake, dug deeper into its technical implications. In this post, we will review the architectural elements of the virtual data lake, and will discuss why a virtual data lake can play a key role for the data scientist.
Data scientist are the major users of data lakes, and probably the demographic that can benefit the most from the virtual version of the concept. For a data scientist, a data lake provides the place to store and massage the data they need, with the capability of dealing with large volumes. At the same time, it provides a modern tool for science with a rich ecosystem of tools and libraries for machine learning, predictive analytics and artificial intelligence. The Virtual Data Lake needs to fulfill those same needs and provide some extra value.
The workflow of a data scientist with a Virtual Data Lake
A typical workflow for a data scientist is as follows:
- Identify data useful for the case
- Store that data into the lake
- Cleanse data into a useful format
- Analyze data
- Execute data science algorithms (ML, AI, etc.)
- Iterate process until valuable insights are produced
In this kind of flows, most of the time is usually spent in the first three steps. See for example, the AI Hierarchy of Needs, summarized in the figure below:
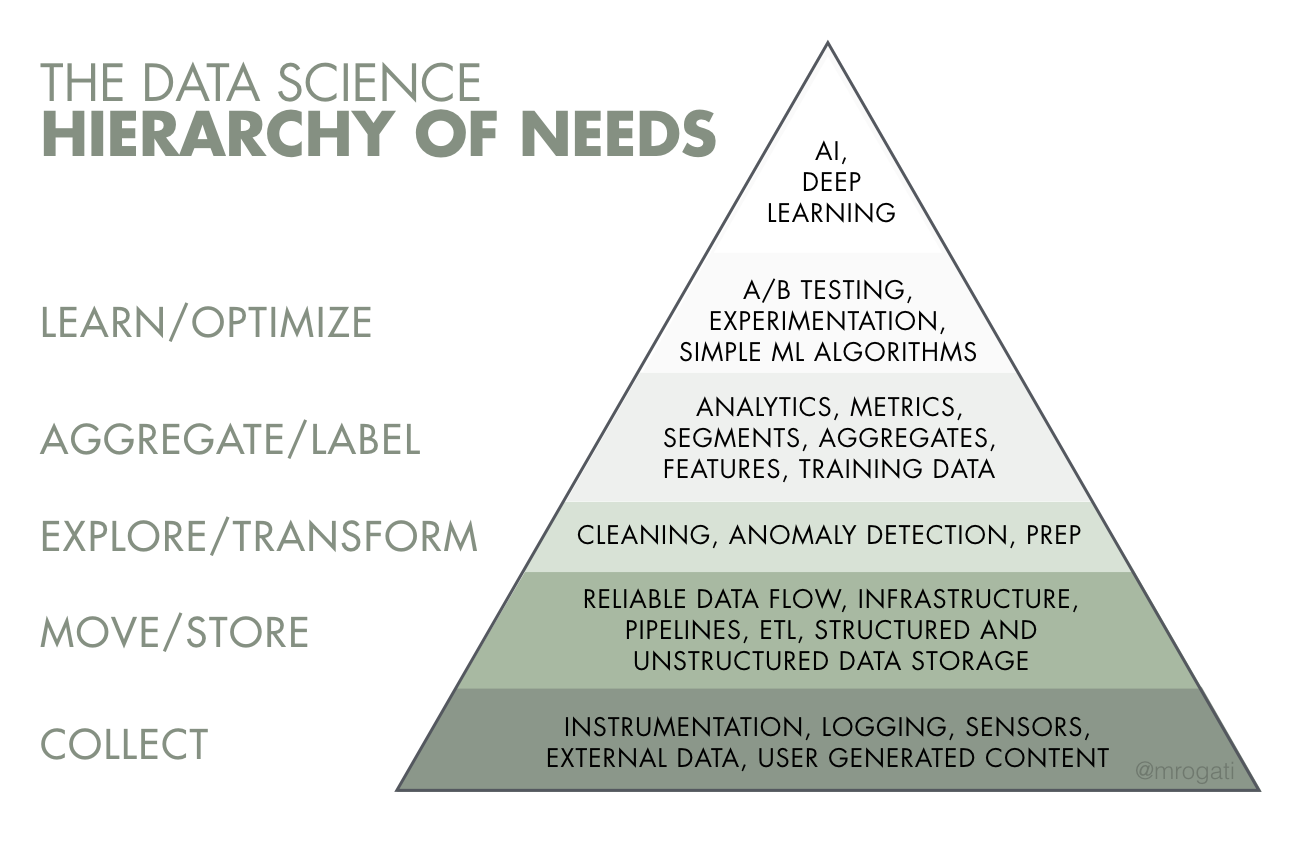
The core skills of the data scientist focus on the tasks on top of the pyramid. However it’s on the areas at the bottom where most of the time and effort is spent. It is also in the bottom areas where a Virtual Data Lake can benefit the data scientist the most. We have previously discussed this topic in the blog, in the post “A Virtual Sandbox for Data Scientists”.
Let’s review how data scientists can use a Virtual Data Lake with Denodo to their advantage
Identify useful data
- Use the Denodo Data Catalog to identify potential sources for the current study.
- Since all data is available through the data lake, there is no need to ask for new credentials, or to get familiar with external systems or languages (e.g. data in SAP, cloud APIs, noSQL databases, etc.)
- Searches can start with metadata (“where can I find social security numbers”, “where can I find details of transactions”), or with data itself (“do we have data for ‘John Smith’?”).
- Denodo’s Data catalog exposes technical metadata (data types, column names, etc) and business metadata (descriptions, categories, tags, etc.)
- Denodo provides a data indexer and search engine (can also integrate with ElasticSearch) to enable keyword-based search on the content of the tables
- Data can be previewed directly in the catalog to quickly validate if the data is useful
- Users can add their own comments to help others in the future
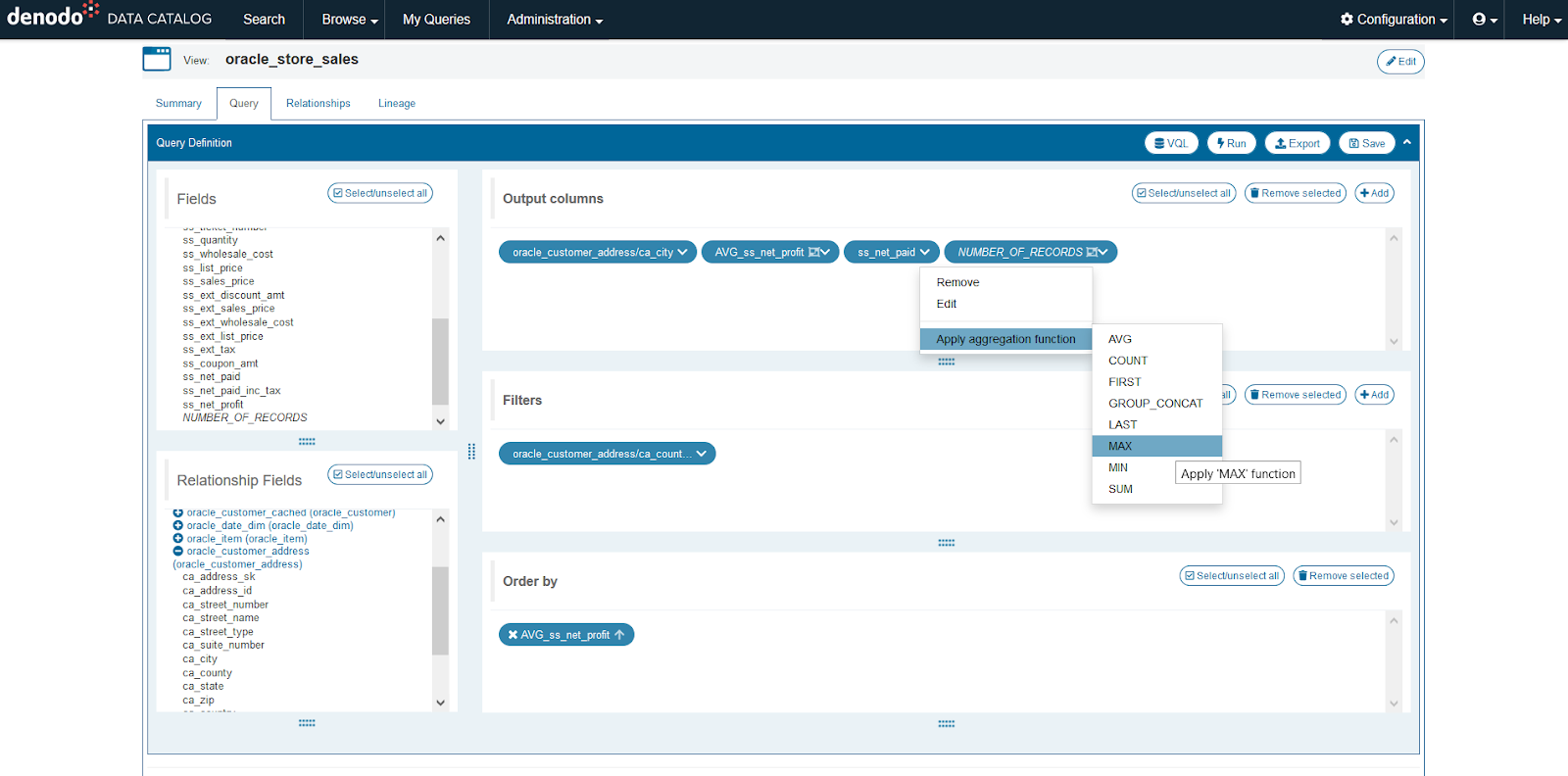
Denodo’s Data Catalog web query wizard
Store that data into the lake
- Since real time access via the virtual layer is already possible, this step may not be necessary. SQL queries to Denodo will be translated to the corresponding technology of the data source (For example, a call to a table from a web application will translate SQL to an HTTP call) and Denodo will respond with a result set.
- If for some scenarios direct access is not appropriate, the scientist can easily persist that same data in the lake using Denodo.
- Denodo can read data from the sources, create a table in the lake following the schema and data types, and upload content via Parquet files (optionally compressed) to the cluster. Denodo uses multiple chunks uploaded in parallel to improve its efficiency.
- This process is completely transparent for the scientists. They have two options:
- Enable and load the cache for that view
- Create a Denodo remote table, which gives them the freedom to choose the final target system, location and table name
- Compared with other ingestion methods, this approach has multiple advantages:
- It preserves the original metadata. The lineage of the model still points to the original source. It’s seamless to restore when the source changes.
- It supports incremental loads, avoiding full refresh loads.
- It can be controlled graphically from Denodo’s UI, or via SQL commands from an external application or notebooks.
- It’s simpler and faster than other alternatives, like Sqoop, ETL tools, or frameworks like Spark data frames.
Cleanse data into into a useful format
- Combine and transform data to create the dataset that will be used as the input for the data analysis.
- Since Denodo provides multi-source federation capabilities, data can be enriched and crossed with another source. For example, device readings can be extended with the details of the contract of the owner, from the CRM. Marketing data from a cloud application can be cross-referenced with the impact in sales from the EDW, etc.
- Denodo provides a large library of SQL-like transformations, that allows users to manipulate the format of the data, perform mathematical operations, and many more.
- Derived models and calculations can be defined via SQL in a shell or Notebook like Zeppelin or Jupyter, or in Denodo’s Design Studio, with powerful graphical wizards. Both modes are equivalent and interchangeable. A model created graphically can be edited in SQL, and vice versa.
- Like in the section above, the results of the models can be persisted if necessary.
- As an advantage from other methods, Denodo will keep the original lineage and transformations used to define the model. Therefore, tasks like modifying the transformations or tracing data back to the source become very easy.
- When dealing with large data volumes during execution, even for queries involving data from outside the lake, Denodo’s engine can use the lake cluster as the execution engine, taking advantage of the cluster capabilities for massively parallel processing. For more details on this area, please visit this article centered in the performance optimizations of the virtual data lake.
- For ongoing work, scientist can also use temporary tables (associated to the session), that will disappear when the session ends.
Analyze data
- Once data is clean, it can be analyzed and cross checked with other tables to define derived metrics, usually with a higher aggregation grain.
- Although with a different goal in mind, the consideration described in the previous step also apply for data analysis. Denodo can combine data from inside and outside the physical lake, using its Cost Based Optimizer to orchestrate the execution in the most efficient way.
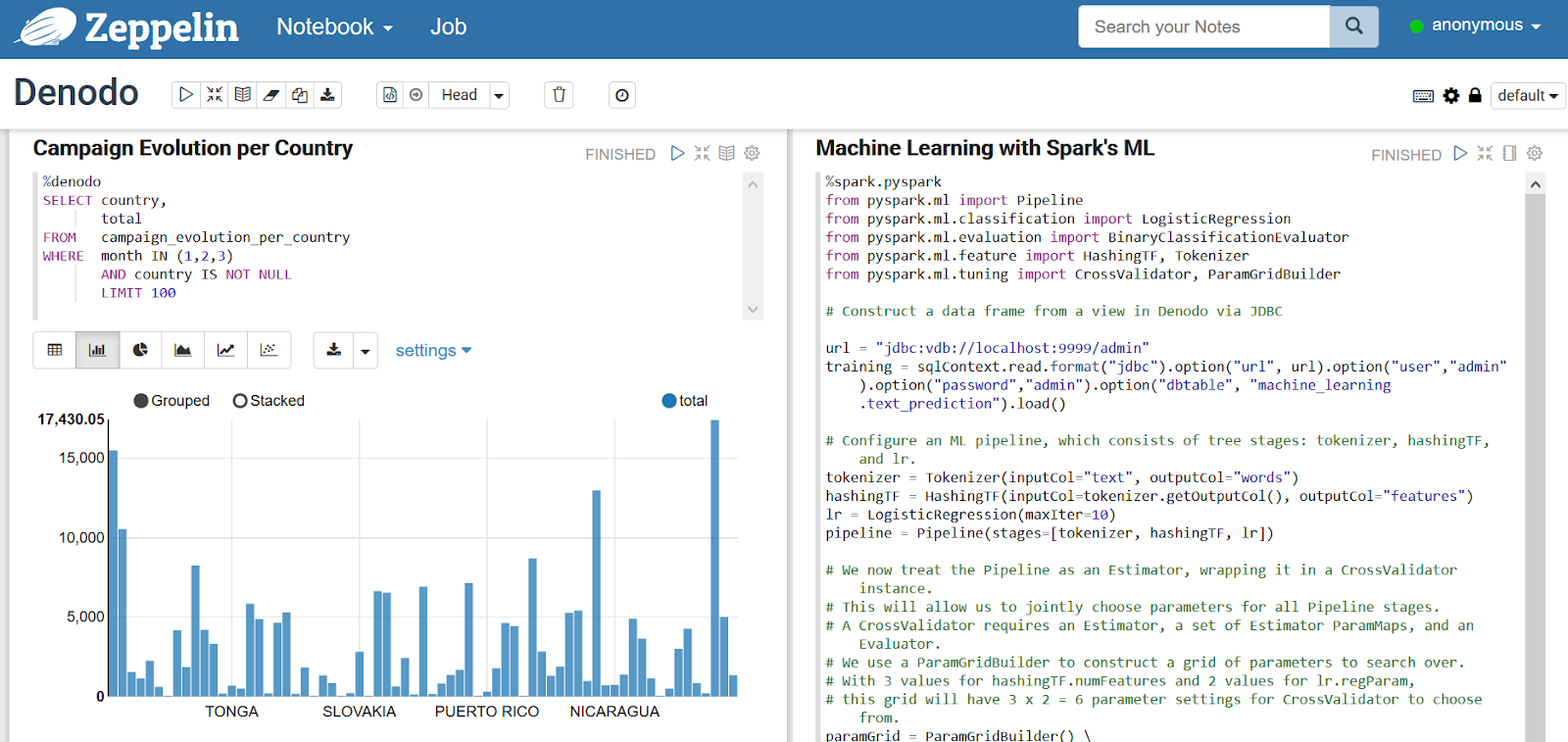
Zeppelin running queries on Denodo and Spark ML accessing Denodo via Data Frames
Execute data science algorithms (ML, AI, etc.)
- Use the tool of choice for Machine Learning, Deep Learning, Predictive Analytics, etc. The tool can access data directly from Denodo, from the cluster if persisted, or via a file export
- Denodo can be accessed directly via JDBC and ODBC, which opens the door for most tools and languages (R, Scala, Python, etc.).
- R: R can access Denodo data directly using the package RJDBC
- Scala: since Scala runs on the JVM, it can natively use JDBC
- Python: Denodo is also compatible with Python’s Psycopg2 driver, and can be used with SQLAlchemy
- If the tables created in steps 3. and 4. were persisted in the lake, the scientist could use the native lake libraries, for example Spark’s libraries for Machine Learning and Analytics, or tools like Mahout.
- Denodo is also accessible via the Data Frames API, which allows for direct use of Denodo tables (not persisted in the lake) with the Spark ML libraries, for example
Iterate process until valuable insights are produced
- This process usually involves small changes and repetitions until the right results are generated. A virtual approach to this process adds many benefits:
- Denodo can detect changes in the sources and propagate those through the derived models
- Data lineage preserves the data flows and transformations from source to final analysis
- Graphical wizards allow for quick modification without the need to re-write SQL
- Final results can be saved, documented, and promoted to a higher environment to be consumed by Business Analysts
Conclusions
As you can see, data virtualization can play a key role in the toolkit of the data scientist. It can accelerate the initial phases of the analysis, where most time is consumed. It integrates with the traditional data science ecosystem, so there is no need to move the data scientist into a different platform. Results are easily publishable via the same platform for non-technical users to review and use, without the need for advanced knowledge of the Big Data ecosystem. As a result,
- Development is shortened
- Replication and storage is reduced
- Final results are published in a consistent manner for business analysts
Check out my first article in the data lake series: “Rethinking the Data Lake with Data Virtualization” where I introduced the idea of the logical data lake, a logical architecture in which a physical data lake augments its capabilities by working in tandem with a virtual layer.

- Improving the Accuracy of LLM-Based Text-to-SQL Generation with a Semantic Layer in the Denodo Platform - May 23, 2024
- Denodo Joins Forces with Presto - June 22, 2023
- Build a cost-efficient data lake strategy with The Denodo Platform - November 25, 2021
Very cool article Pablo!
Thanks Mike. It’s definitely a scenario where we are currently seeing a lot of traction
I am heartily impressed by your blog and learn more from your article. Thank you so much for sharing with us. Here is the best solution. If you want to look please visit here Data Lake Tool